De vez en cuando, es bueno recordarle a la gente la complejidad de un producto como SQL Server. Las partes internas son tan amplias y complejas que nos perdemos fácilmente y seguimos lo que sigue siendo más fácil en nuestras mentes, en lugar de entender la imagen completa. De vez en cuando, es bueno recordarle a la gente la complejidad de un producto como SQL Server. Las partes internas son tan amplias y complejas que nos perdemos fácilmente y seguimos lo que sigue siendo más fácil en nuestras mentes, en lugar de entender la imagen completa.
En este caso, le presentaré algunos beneficios que puede encontrar al no seguir las mejores prácticas, no es necesario decir que le mostraré cómo lograr el mismo siguiendo también las mejores prácticas. Complicado, ¿no?.
Antecedentes
En el pasado, alguien decidió que era una gran idea (nótese la ironía) permitir que se almacenaran cualquier tipo de datos dentro de una base de datos, y eso incluye texto y objetos binarios ‘ilimitados’ (imágenes por ejemplo) de hasta 2GB, por lo TEXT, NTEXT e IMAGE se agregaron a SQL Server como tipos de datos.
Luego las cosas se pusieron un poco modernas y fueron reemplazadas por VARCHAR (MAX), NVARCHAR (MAX) y VARBINARY (MAX) y los anteriores fueron marcadas como ‘Obsoleto’, lo que significa probablemente no mucho, ya que en el momento de escribir eso, todavía están ahí.
Caso real
Tengo bases de datos, como cualquier buen DBA, y algunas están llenos de documentos XML almacenados como [N]TEXT. Algunas tablas son realmente grandes, déjame mostraros.
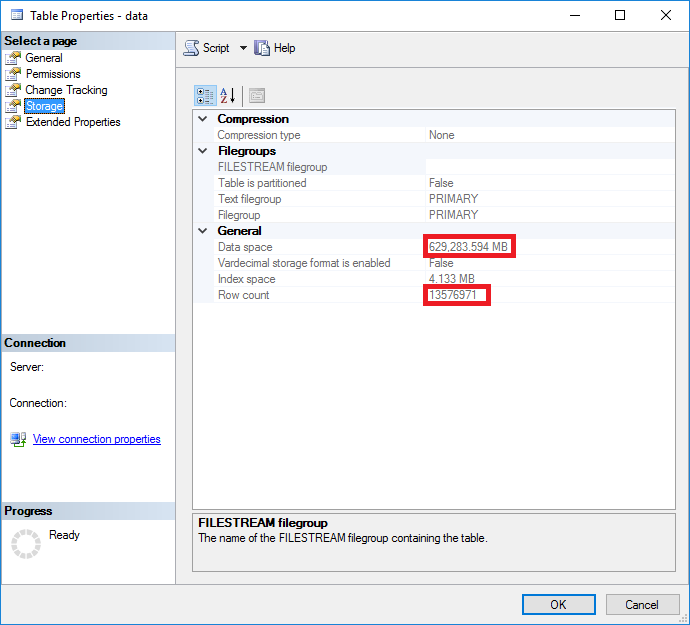
Entonces una tabla con 13576971 filas y 629,398MB que son documentos XML, no está mal … Sabemos que SQL Server almacena datos en páginas de 8kb, por lo que aproximadamente esta tabla usa 80548829 páginas.
Esta tabla contiene algunas columnas con metadatos que ayudan a ubicar el documento xml, por lo que si consultamos la tabla para obtener todos los documentos que coinciden con ciertas condiciones (no hay índices en esa columna) tendremos que escanear toda la tabla para recuperar esos documentos .
La siguiente consulta no recupera ninguna fila, ya que la fecha de creación no puede ser mayor que la actual.
USE [my_database] GO SET STATISTICS IO ON GO SELECT * FROM dbo.data WHERE created > DATEADD(DAY, 1, GETDATE()) GO
Y como era de esperar, tenemos que escanear toda la tabla para satisfacer la consulta.
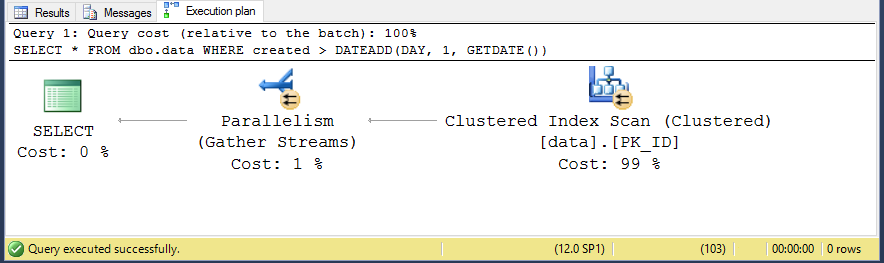
Todo bien entonces, entonces si tenemos que escanear el índice agrupado (tabla), podemos suponer que el número de páginas leídas será bastante cercano a los 80,5M de páginas que hemos visto antes, ¿no?
Revisemos la pestaña ‘Mensajes’.
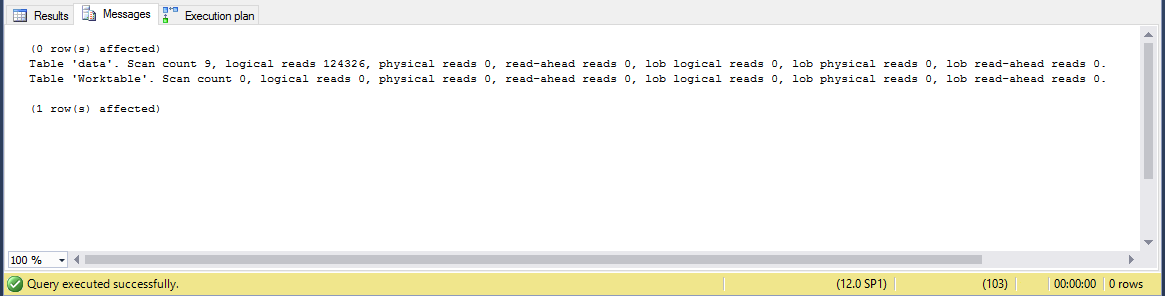
¿Ejem? ¿Solo 125k? ¿Cómo?
Explicación
Dijimos que los datos en SQL Server se almacenan en 8k páginas, pero estas páginas se administran en una o más unidades de asignación dependiendo de los tipos de datos.
Si echamos un vistazo a Books online, vemos que los diferentes tipos de unidades de asignación son
- IN_ROW_DATA, que contiene todos los datos excepto datos de LOB
- LOB_DATA, donde se almacenan los tipos de datos LOB ( text, ntext, image, xml y tipos de datos MAX )
- ROW_OVERFLOW_DATA, a veces los datos de longitud variable (no BLOB) pueden acabar aquí si la longitud total excede el límite de fila de 8060 bytes
Para ver la distribución de datos con más detalle, necesitamos dividir el total por tipo de unidad de asignación.
SELECT OBJECT_NAME(ix.object_id)
, ix.name
, au.*
, p.rows
FROM sys.indexes AS ix
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
WHERE ix.object_id IN (OBJECT_ID('dbo.Data'))

Podemos ver que nuestra tabla está distribuida en dos unidades de asignación diferentes, IN_ROW_DATA y LOB_DATA, lo que significa que todos los datos dentro de las columnas de los tipos de datos anteriores terminarán en diferentes tipos de páginas de forma predeterminada, independientemente del tamaño de los datos.
Este es el comportamiento predeterminado para los tipos de datos LOB antiguos, que se almacenarán por separado, pero los nuevos tipos de datos LOB (MAX) de forma predeterminada tratarán de ponerlos en fila si son lo suficientemente pequeños como para caber.
Si algunos de esos documentos estuvieran almacenados en la filas, daría como resultado un aumento importante en el número de páginas para escanear, lo que en este caso, afectaría negativamente al rendimiento.
Hay que tener en cuenta que para el escaneo de tablas solo hemos utilizado las páginas IN_ROW_DATA, lo que lo hace mucho más liviano que si tuviéramos que escanear la suma de todas las páginas.
La nueva forma de hacer las cosas
Como dije, podemos lograr el mismo comportamiento utilizando los nuevos tipos de datos (MAX) utilizando el procedimiento almacenado sp_tableoption especificando que la opción ‘tipos de valores grandes fuera de la fila’ es verdadera.
Este SP funcionará al contrario para hacer que los tipos de datos obsoletos también se comporten como los nuevos al especificar un valor entre 24 y 7000 para la opción ‘texto en fila’.
Por lo tanto, tenemos el control total de dónde se almacenan los datos de LOB, para que coincidan con nuestro patrón de uso.
Conclusión
Cuando instalamos SQL Server, este viene con una configuración predeterminada y lo mismo que solemos cambiar configuracien a niver de servidor y de las base de datos por varias razones, el hecho de poder decidir dónde se almacenarán nuestros datos abre muchas posibilidades para administrarlo mejor y obtener el mejor rendimiento para nuestras consultas.
En este caso, usar los tipos de datos obsoletos, debido al almacenamiento predeterminado, nos ha beneficiado a la hora de tener que escanear una tabla grande como esta, pero lo mismo se puede lograr ajustando los nuevos tipos de datos, por lo que no es realmente necesario para seguir usando los tipos de datos obsoletos.
Hay algunos enlaces que no quiero terminar sin compartirlos.
- Organización de tablas e índices
- Datos en fila
- Datos de desbordamiento de fila que exceden 8KB
- sp_tableoption
- Importancia de elegir la técnica de almacenamiento LOB correcta
¡Gracias por leer!
You should mention the drawback on this behavior.
When you have a table with e.g. 5 varchar(max) data types and each (in every row of the table) contains usually only up to 50 chars (e.g. comment fields, that COULD be big but will be usually very short), it would take some additional reads, when you select a row by its primary key. For single reads it would be regardless, but sometimes you have a query with nested loops, where it will blow up your total read pages count, when even the shortest comment will be stored in the LOB-pages.
Thanks for your comment!
You’re right, there are benefits and drawbacks, the important thing is to know how the data will be accessed.
If you need, for instance, to filter on those columns, accessing each document for a table scan will be very expensive.
You can think of it like if you have to tables (vertical partitioning, from Paul Randal’s link) as far as you access the «metadata» and not multiple documents at a time, you’re better off with either 2 tables or Off-Row storage, otherwise, yes, you probably get better performance using In-Row,
Like always, it depends. Cheers.