En este post quiero mostrar como crear recopiladores de datos de en el monitor de rendimiento de Windows y las diferentes opciones para guardar esos datos y posteriormente insertar en una base de datos SQL Server Todavía no es un año nuevo, pero ya he hecho mis buenos propositos y eso incluye escribir más, así que me he puesto manos a la obra.
Cuando las cosas van mal, y con esto quiero decir cualquier cosa que pare o ralentice nuestro entorno de producción, nosotros como DBA necesitamos tener datos para respaldar nuestras palabras, por lo que si decimos que SQL Server es tan rápido o tan lento como de costumbre y el problema debe estar en otro sitio, necesitamos datos para poder probarlo.
Antecedentes
Una excelente forma de obtener métricas de rendimiento viene integrada en el sistema operativo Windows, el monitor de rendimiento nos permite crear Conjuntos de recopiladores de datos definidos por el usuario, simplemente ejecutamos perfmon.exe y se abrirá la consola de administración.
Lo cierto es que tenemos muchisimos contadores para elegir y no es el proposito de este post explicar para que sirve cada uno de ellos, sino centrarnos en cómo vamos a capturar los datos y, lo más importante, cómo los haremos llegar a SQL Server y luego procesarlos esos datos para obtener resultados significativos.
Crear un recopilador de datos basado en una plantilla
Una vez que hayamos abierto el monitor de rendimiento si queremos crear un nuevo recopilador de datos, tendremos que hacer algunas elecciones en el asistente.
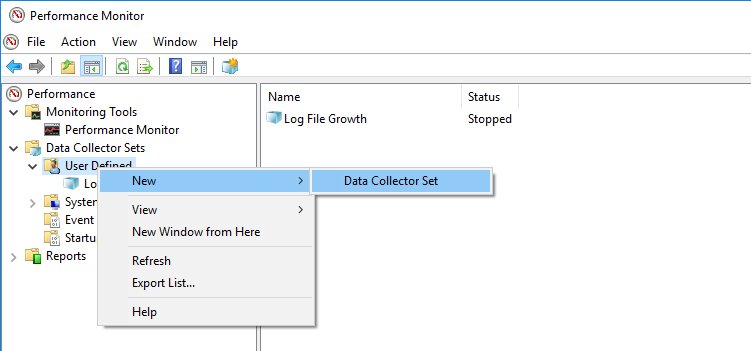
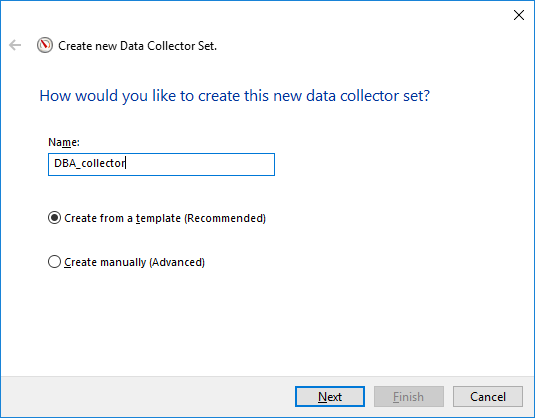
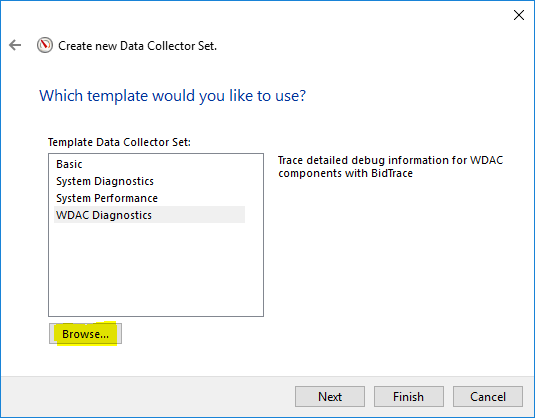
Aquí os dejo la plantilla que he usado para crear mi Recopilador de datos, basta con ponerlo en un archivo XML y cambiar algunos de los contadores que están relacionados con SQL Server.
Cuando digo MSSQL$MSSQL2016, es porque este contador se refiere a una instancia llamada MSSQL2016. Si esa fuera la instancia predeterminada, sería solo «SQL Server».
Ejemplo: <Counter>\SQL Server:Buffer Manager\Page life expectancy</Counter>
Una vez que lo ajusteis, estamos listos para comenzar.
<?xml version="1.0" encoding="UTF-16"?> <DataCollectorSet> <Status>0</Status> <Duration>0</Duration> <Description> </Description> <DescriptionUnresolved> </DescriptionUnresolved> <DisplayName> </DisplayName> <DisplayNameUnresolved> </DisplayNameUnresolved> <SchedulesEnabled>-1</SchedulesEnabled> <Name>DBA_Collector</Name> <RootPath>C:\PerfLogs\Admin\DBA_collector</RootPath> <Segment>-1</Segment> <SegmentMaxDuration>86400</SegmentMaxDuration> <SegmentMaxSize>0</SegmentMaxSize> <SerialNumber>348</SerialNumber> <Server> </Server> <Subdirectory> </Subdirectory> <SubdirectoryFormat>3</SubdirectoryFormat> <SubdirectoryFormatPattern>yyyyMMdd\-NNNNNN</SubdirectoryFormatPattern> <Task> </Task> <TaskRunAsSelf>0</TaskRunAsSelf> <TaskArguments> </TaskArguments> <TaskUserTextArguments> </TaskUserTextArguments> <UserAccount>SYSTEM</UserAccount> <StopOnCompletion>0</StopOnCompletion> <PerformanceCounterDataCollector> <DataCollectorType>0</DataCollectorType> <Name>DataCollector01</Name> <FileName>DBA_DataCollector</FileName> <FileNameFormat>3</FileNameFormat> <FileNameFormatPattern>yyyyMMdd\_HHmmss</FileNameFormatPattern> <LogAppend>0</LogAppend> <LogCircular>0</LogCircular> <LogOverwrite>0</LogOverwrite> <DataSourceName> </DataSourceName> <SampleInterval>15</SampleInterval> <SegmentMaxRecords>0</SegmentMaxRecords> <LogFileFormat>3</LogFileFormat> <Counter>\Memory\Available MBytes</Counter> <Counter>\Paging File(*)\% Usage</Counter> <Counter>\MSSQL$MSSQL2016:Buffer Manager\Page life expectancy</Counter> <Counter>\MSSQL$MSSQL2016:Buffer Node(*)\Page life expectancy</Counter> <Counter>\MSSQL$MSSQL2016:General Statistics\User Connections</Counter> <Counter>\MSSQL$MSSQL2016:Memory Manager\Memory Grants Pending</Counter> <Counter>\MSSQL$MSSQL2016:SQL Statistics\Batch Requests/sec</Counter> <Counter>\MSSQL$MSSQL2016:SQL Statistics\SQL Compilations/sec</Counter> <Counter>\MSSQL$MSSQL2016:SQL Statistics\SQL Re-Compilations/sec</Counter> <Counter>\PhysicalDisk(*)\Avg. Disk Queue Length</Counter> <Counter>\PhysicalDisk(*)\Current Disk Queue Length</Counter> <Counter>\PhysicalDisk(*)\Disk Reads/sec</Counter> <Counter>\PhysicalDisk(*)\Disk Writes/sec</Counter> <Counter>\PhysicalDisk(*)\Avg. Disk sec/Read</Counter> <Counter>\PhysicalDisk(*)\Avg. Disk sec/Write</Counter> <Counter>\PhysicalDisk(*)\Avg. Disk Read Queue Length</Counter> <Counter>\PhysicalDisk(*)\Avg. Disk Write Queue Length</Counter> <Counter>\System\Processor Queue Length</Counter> <Counter>\Processor(*)\% Processor Time</Counter> </PerformanceCounterDataCollector> <DataManager> <Enabled>0</Enabled> <CheckBeforeRunning>0</CheckBeforeRunning> <MinFreeDisk>0</MinFreeDisk> <MaxSize>0</MaxSize> <MaxFolderCount>0</MaxFolderCount> <ResourcePolicy>0</ResourcePolicy> <ReportFileName>report.html</ReportFileName> <RuleTargetFileName>report.xml</RuleTargetFileName> <EventsFileName> </EventsFileName> </DataManager> </DataCollectorSet>
Y después de elegir la plantilla (opcional) o seleccionar manualmente los contadores, tenemos que decidir dónde almacenar los archivos de salida y se ejecutarán las credenciales debajo de él, puede dejar los valores predeterminados allí.
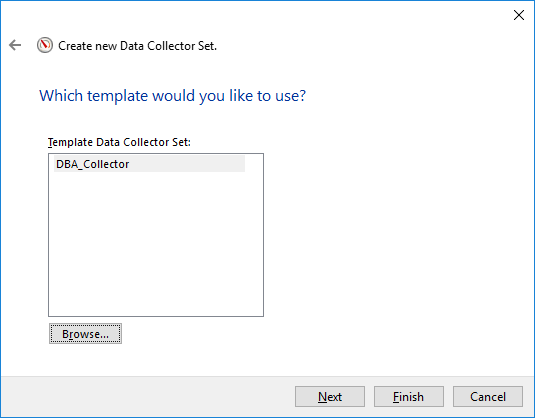
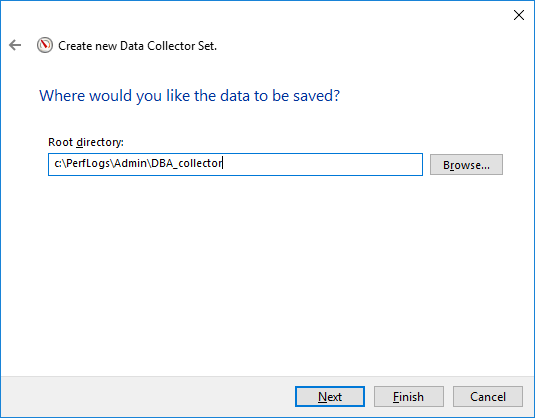
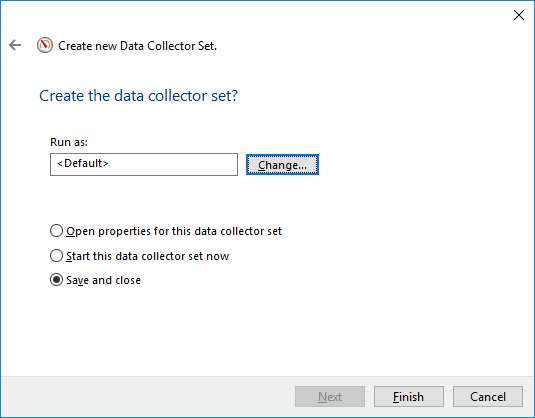
Así que ahora tenemos nuestro recopilador de datos creado, podemos ir a propiedades para ver cómo se ve o quizás agregar más contadores, quién sabe 🙂
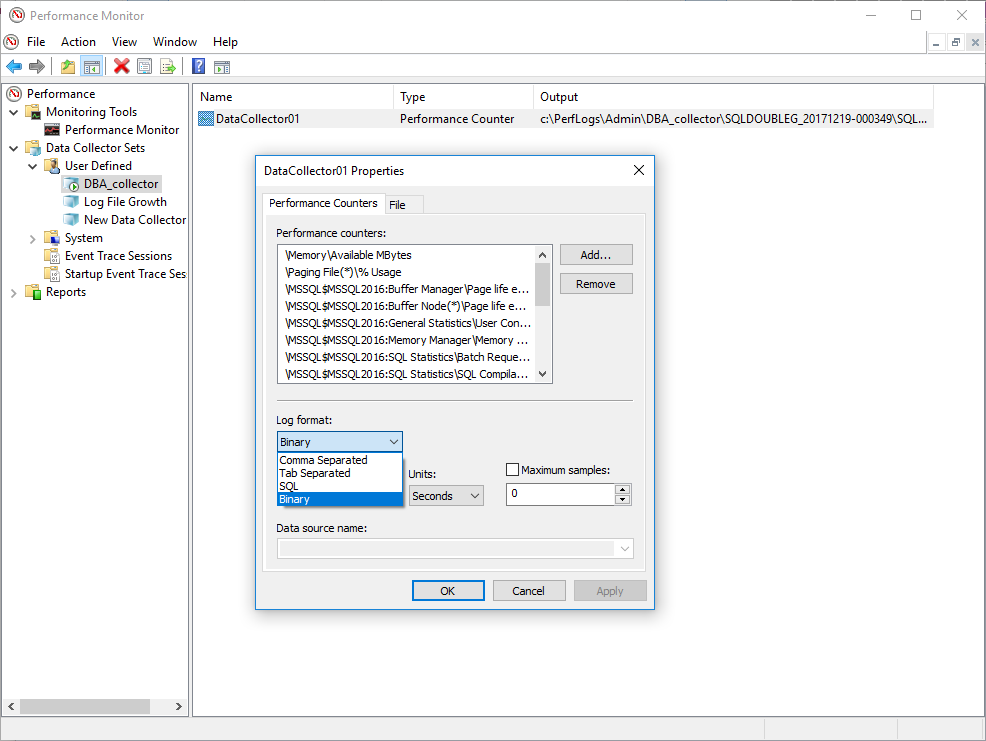
Existen diferentes opciones para obtener todos estos datos generados y depende totalmente de nosotros decidir cuál es la mejor, pero dejadme que os muestre cuales son.
Las diferentes opciones son
- Coma Separated, el archivo de valores separados por coma (CSV) bastante conocido
- Tab Separated, practicamente lo mismo que el de arriba, pero separado por tabuladores
- SQL, esto escribirá directamente a una base de datos que definamos
- Binario, crea archivos binarios
Cada uno de ellos tiene sus pros y contras
| Formato | Requisitos de almacenamiento | Se puede abrir con | Se puede importar a SQL |
| Comma Separated | Bajo | Hojas de cálculo, Editor de texto | Sí |
| Tab Separated | Bajo | Hojas de cálculo, Editor de texto | Sí |
| SQL | Solo en Base de datos | SQL Server | Sí |
| Binary | Alto | Performance monitor | Sí |
A mi parecer es que realmente depende de cómo queramos usar la salida aparte de insertarla en una base de datos de SQL Server.
Separados por comas y separados por tabuladores son perfectos si quieres abrirlos con cualquier programa de hojas de cálculo como Excel, también los requisitos de almacenamiento son menores que los archivos binarios, en mi experiencia de 1 a 4 para la misma cantidad de datos, así que si te preocupa el almacenamiento, los archivos de texto simple puede ser tu mejor opcion.
El formato binario se puede abrir con el Monitor de rendimiento y muestra los diferentes contadores de varias maneras, al igual que cuando los vemos en tiempo real.
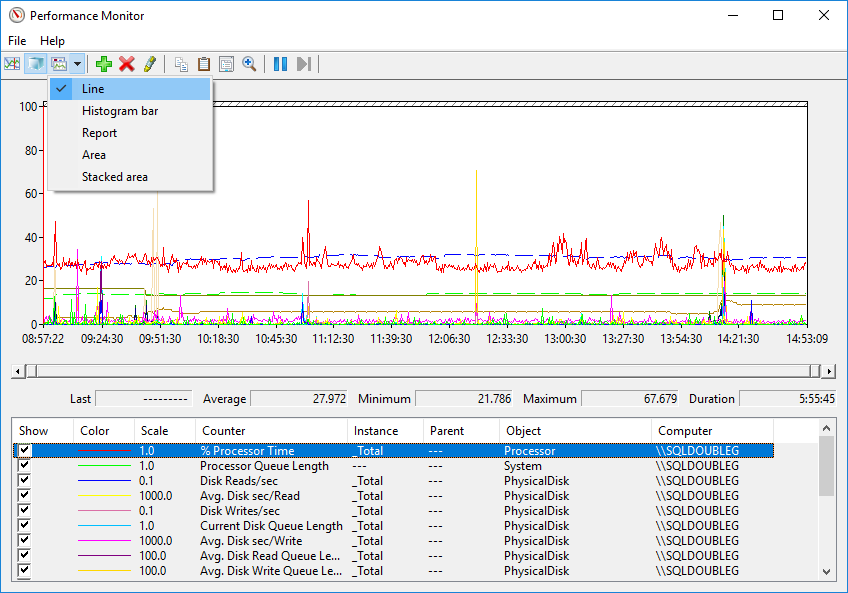
Insertar los datos directamente en una base de datos puede sonar como el camino a seguir, al fin y al cabo ese es el propósito de este post, pero a no ser que procesemos y/o agreguemos toda esa información, en poco tiempo tendremos una gran cantidad de datos, así que yo sería prudente, ya que prefiero tener muchos archivos en una carpeta compartida y cargar en SQL solo aquellos que me interesan, antes que tener otra base de datos monstruosa para mantener.
Yo he optado por volcar los datos en un archivo binario para poder mostraros también los resultados, pero definitivamente debeis eligir el que más os convenga.
Conclusión
Hasta ahora hemos visto cómo crear y configurar un nuevo recopilador de datos y las diferentes formas que podemos obtener su resultados.
Es muy importante elegir con cautela los contadores que queremos monitorear, porque la cantidad de información puede ser abrumadora y al final ser contraproducente.
Y también hemos visto cómo los diferentes formatos de salida pueden traer pros y contras, así que de nuevo tenemos que pensar cuidadosamente cómo queremos consumirlos. Sin embargo, esto se puede cambiar en cualquier momento, de modo que si veis que el formato eligido cuando lo creamos no funciona, simplemente podemos cambiarlo.
De momento eso es todo, la próxima semana veremos cómo podemos insertar toda esta información en SQL Server y luego cómo procesarla para recuperar los datos de una manera más significativa.
Espero que hayais disfrutado de la lectura y estad atentos a la segunda parte.
Gracias!