This post wants to show some performance improvements we may have by doing things the way we’ve been told not to When it comes to technical subjects like databases, we must always look for proven solutions and best practices, which usually take us from A to B in the most efficient way. Usually.
But what happens if one of those approaches considered best practices is not as efficient as the one supposed to be the baddie?
DISCLAIMER: This is a demonstration which shows a fact or series of facts, not pretending to set or contradict any best practice.
With that said, let’s start with the topic in title.
In SQL Server, there are a number of reasons why you want to have most of (if not all) your tables created as clustered indexes and not heaps. There are also lots of information about how we should carefully choose on which column[s] from our tables we would create them as this choice will help our performance in general. My favorite expert for this topic is Kimberly Tripp (b|t), so I strongly recommend reading this, this and this. Just checking the dates on the posts, you can picture how long this has been around.
But sometimes we can find some behaviours that contradicts all we’ve learned and get unexpected benefits from doing things “wrong”.
Let’s set up a small demo where to see this in action, starting by restoring a copy of [AdventureWorksXXXX] on our server, in my case the 2014 version of it
--===============================================================================================
-- Set up
--===============================================================================================
USE master
GO
IF DB_ID('AdventureWorks2014') IS NOT NULL BEGIN
ALTER DATABASE AdventureWorks2014 SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE AdventureWorks2014
END
RESTORE FILELISTONLY FROM DISK = '.\AdventureWorks2014.bak'
RESTORE DATABASE AdventureWorks2014
FROM DISK = '.\AdventureWorks2014.bak'
WITH RECOVERY
, MOVE 'AdventureWorks2014_Data' TO 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQL2014\MSSQL\DATA\AdventureWorks2014_Data.mdf'
, MOVE 'AdventureWorks2014_Log' TO 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQL2014\MSSQL\DATA\AdventureWorks2014_Log.ldf'
GO
And then we create a HEAP table by simply SELECTing one INTO another
USE AdventureWorks2014 GO SELECT * INTO Person.Address_HEAP FROM Person.Address
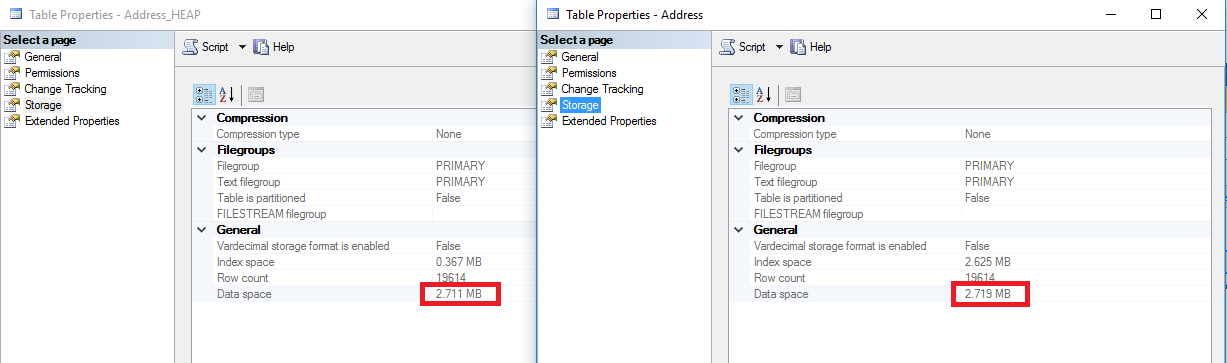
The first [unexpected] benefit is that the HEAP is smaller than the Clustered Index.
Since there is no B-Tree to navigate to our records, those sort of pages are not required in a HEAP, so the result is a slightly smaller table, not enough to say it’s and advantage but there it is.
So, to the point, let’s create a nonclustered index on our HEAP to match an existing one on the clustered table.
USE AdventureWorks2014 GO CREATE NONCLUSTERED INDEX [IX_Address_StateProvinceID] ON [Person].[Address_HEAP] ( [StateProvinceID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
Now we need a bit of imagination but you’ll see it makes sense (hopefully)
We have our 2 tables with a non clustered index on the column [StateProvinceID], so the query optimizer is likely to choose the combination of Non Clustered Index Seek + Lookup if we query the table for a specific value that do not exceed the tipping point.
In this case I will force the optimizer to choose that plan like we are in a SP that suffers from parameter sniffing, so take note because that is a common behaviour.
USE AdventureWorks2014 GO SET STATISTICS IO, TIME ON DECLARE @StateProvinceID INT = 9 SELECT * FROM Person.Address WHERE StateProvinceID = @StateProvinceID OPTION (OPTIMIZE FOR (@StateProvinceID = 1)) GO DECLARE @StateProvinceID INT = 9 SELECT * FROM Person.Address_HEAP WHERE StateProvinceID = @StateProvinceID OPTION (OPTIMIZE FOR (@StateProvinceID = 1))
As expected, on both queries the plan is identical with the exception of the Key Lookup versus the RID Lookup
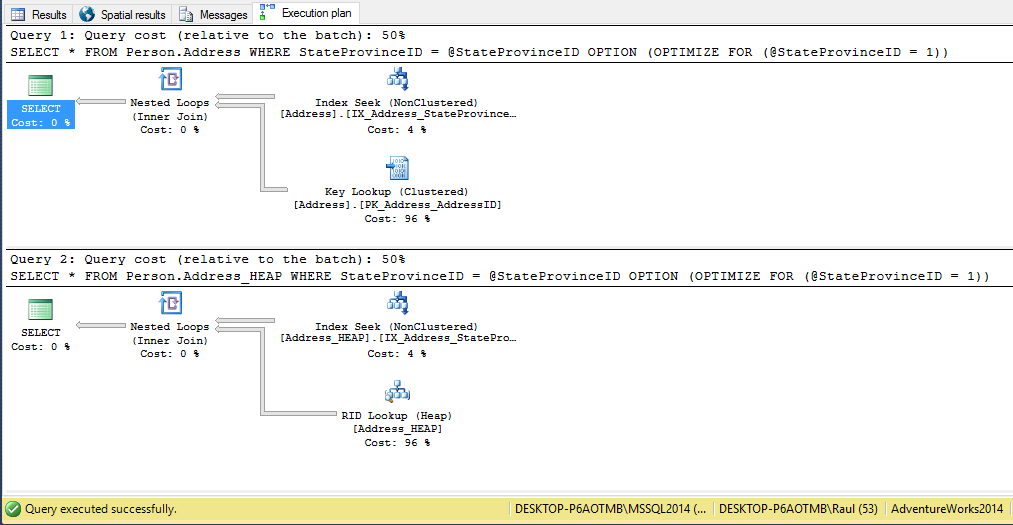
Both plans are the same but let’s get a better look to STATISTICS IO to see what was going on under the hood.
/* (4564 row(s) affected) Table 'Address'. Scan count 1, logical reads 9139, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) SQL Server Execution Times: CPU time = 15 ms, elapsed time = 176 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. (4564 row(s) affected) Table 'Address_HEAP'. Scan count 1, logical reads 4577, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) SQL Server Execution Times: CPU time = 0 ms, elapsed time = 95 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. */
You can see we need almost double the reads (and time) to finish with the lookups in the clustered index versus the HEAP.
The explanation is that for every lookup, you must locate the row, and that is done in different ways
– If there is a clustered index, the non clustered index references a row by the clustering key, so we must check the upper levels of the B-tree to locate the row at the leaf levels.
– However in the HEAP, rows are uniquely identified by a RID which points exactly to a specific file, page and slot in our database, and that’s the only needed by the storage engine to go fetch that row, so the ratio of reads per fetched row looks more like 1:1 as opposed to the 2:1 in the clustered index in this example.
Conclusion
Most of the time following best practices will result in a more robust a fast performing database, but as always there are some behaviors that might contradict them.
The takeaway of this post is that you do not have to assume best practices are always right for each and every case, it is more important to learn how things work and have the knowledge to decide when those best practices really apply to your environment or workload, because every question may be answered with a big “It Depends”.
As I said in the disclaimer, I’m not saying now you should go drop all your clustered indexes because of this example. There are certainly more benefits doing things right and I only pretend you feel more curious about how SQL Server works.
If you have experience with other anti-patterns which can have a use case, please feel free to share them and thanks for reading.
What about reconfiguring the Clustered Index
SELECT *
INTO Person.Address_StateProv
FROM Person.Address
—
ALTER TABLE Person.Address_StateProv ADD CONSTRAINT
PK_Address_StateProv PRIMARY KEY CLUSTERED
(
AddressID,
StateProvinceID
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
DECLARE @AddressID INT = 9
—
SELECT * FROM Person.Address_StateProv
WHERE AddressID = @AddressID
OPTION (OPTIMIZE FOR (@AddressID = 1))
—
(4564 row(s) affected)
Table ‘Address_StateProv’. Scan count 1, logical reads 340,0,0,0,0,0,0
(1 row(s) affected)
CPU time = 0 ms, elapsed time = 157 ms.
Thanks for your comment, when I run your code I only get 1 row, not the 4564 like in the example, because it accesses the table using the leftmost part of the clustered key (AddressID) which produces the Index seek and removes the need of the lookup, so they can’t be compared to any of the previous.
Cheers
I hastily included the wrong code,
SELECT * FROM Person.Address_StateProv
WHERE StateProvinceID = @StateProvinceID
OPTION (OPTIMIZE FOR (@StateProvinceID = 1))
Yes, now the number of rows match and the reads.
But, if you look at your query plan there is “only” a clustered index scan operator, because since there isn’t any non-clustered index defined for that table, index (non-clustered) seek + key lookup it’s not a valid query plan.
If you just run SELECT * FROM Person.Address_StateProv you can see the number of reads is about 342, same as yours, because the optimizer needs to scan the whole table to determine what the StateProvinceID for each row is.
That’s not necessary when StateProvinceId is the leftmost part of your index key, then a seek can be produced by the optimizer.
Hope that clarifies a bit the example.
Cheers