One of the things you realize with experience is that there is not one absolute truth when speaking about SQL Server… that comes along with the magical answer for most of the questions, “it depends”. But what makes the difference it’s to know what it depends on. One of the things you realize with experience is that there is not one absolute truth when speaking about SQL Server… that comes along with the magical answer for most of the questions, “it depends”.
But what makes the difference it’s to know what it depends on.
Lots have been written, including myself, about the advantage and disadvantages of the different types of tables that exist in SQL Server, Clustered and Heaps.
Today I will again, because at the end of the day, a table is the most basic structure in a database and we need them to store the data, which is indeed the purpose of having a database, right?
When explaining Heaps, Books online specifies that
Most tables should have a carefully chosen clustered index unless a good reason exists for leaving the table as a heap.
So if we see what a clustered index is, we also find in Books online the following definition:
Clustered indexes sort and store the data rows in the table or view based on their key values. These are the columns included in the index definition. There can be only one clustered index per table, because the data rows themselves can be sorted in only one order.
I explained before that this order might be a bit different than you think, but it’s pretty similar, and that bring some benefits, but also some limitations.
Clustered index and page free space
On one hand we have the order of the rows within a clustered index, which is enforced by the clustering key, and on the other we have that each page in SQL Server is exactly 8192 bytes, from those there are 8096 bytes usable and 96 bytes reserved for internal use, not much.
That shouldn’t be a problem when we have narrow tables that mostly use fixed length data types, but if we need to store very variable length columns your rows, your rows can vary from a few bytes to hundreds or thousands. Think about ‘Comments’ or ‘Long description’ we’ve all seen in the wild.
Let’s have a look to some queries
USE master
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test
GO
USE test
GO
CREATE TABLE dbo.clustered_table(
ID INT NOT NULL IDENTITY PRIMARY KEY CLUSTERED
, Col1 NVARCHAR(4000) NOT NULL)
GO
INSERT INTO dbo.clustered_table (Col1) VALUES (REPLICATE (N'A', 3000))
GO 1000
DBCC IND('test', 'dbo.clustered_table', 1)
GO
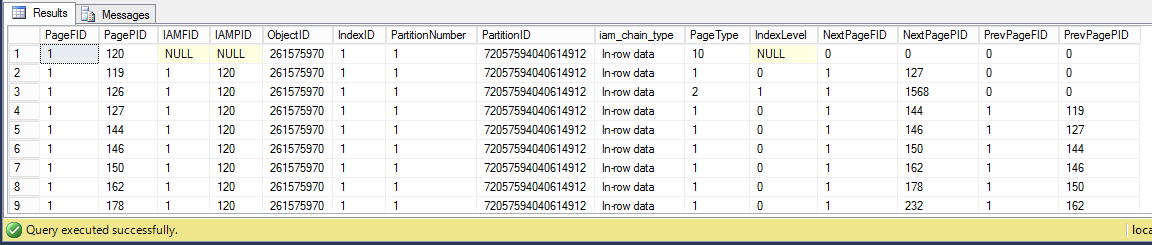
If we inspect one of the data pages we can see interesting information on its header.
DBCC TRACEON(3604)
GO
DBCC PAGE('test',1,144, 3)
GO
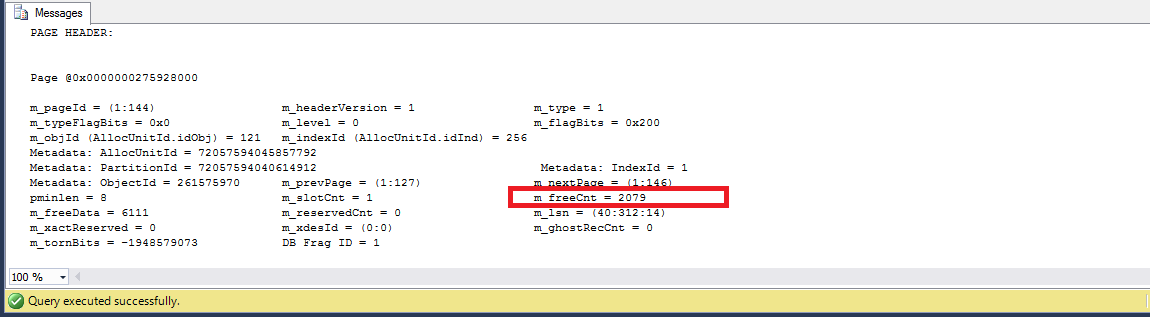
So we have that for each page the free space is 2079 bytes which makes more than 25% of the usable space (8096 bytes) not being used.
Heap Table and page free space
If now we do the same with a HEAP table, what’s going to happen?
USE test
GO
CREATE TABLE dbo.heap_table(
ID INT NOT NULL IDENTITY
, Col1 NVARCHAR(4000) NOT NULL)
GO
INSERT INTO dbo.heap_table (Col1) VALUES (REPLICATE (N'A', 3000))
GO 1000
DBCC IND('test', 'dbo.heap_table', 1)
GO
DBCC TRACEON(3604)
DBCC PAGE('test',1,179, 3)
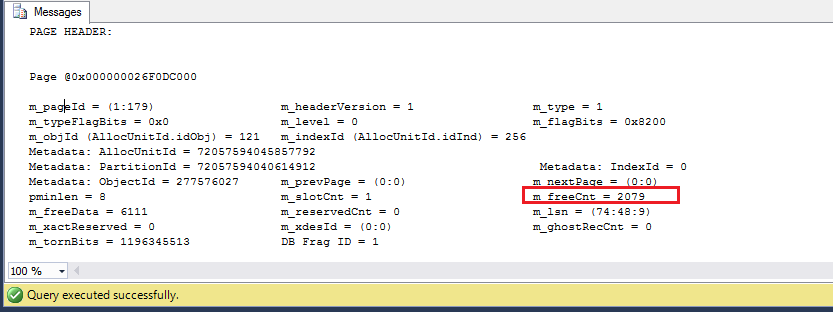
We can also see that the number of pages allocated for each table are pretty similar,
SELECT OBJECT_NAME(ix.object_id)
, ix.name
, au.*
, p.rows
FROM sys.indexes AS ix
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
WHERE ix.object_id IN (OBJECT_ID('dbo.heap_table'), OBJECT_ID('dbo.clustered_table'))
GO

Not very different, right? so where is the benefit? Why am I writing this then? 🙂
Reusing empty space
So far, we’ve seen a similar behavior on both, clustered tables and heap, but we’ll soon see that they behave completely different for the future inserts we have going to make.
USE test GO INSERT INTO dbo.heap_table (Col1) VALUES (REPLICATE (N'A', 500)) INSERT INTO dbo.clustered_table (Col1) VALUES (REPLICATE (N'A', 500)) GO 1000
Let’s first have a look to the number of allocated pages
SELECT OBJECT_NAME(ix.object_id)
, ix.name
, au.*
, p.rows
FROM sys.indexes AS ix
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
WHERE ix.object_id IN (OBJECT_ID('dbo.heap_table'), OBJECT_ID('dbo.clustered_table'))
GO

Now the fun starts, we can observe that while the Clustered index data pages have grown by 143 pages, the Heap has done it for just 2. Where is the trick then?
There is an undocumented function called sys.fn_PhysLocFormatter which does what it says on the tin and returns the formatted physical location of any specific row within a table. (FileId:Page:SlotId)
Let’s have a look to the clustered index first:
SELECT * , sys.fn_PhysLocFormatter (%%physloc%%) AS row_location FROM dbo.clustered_table
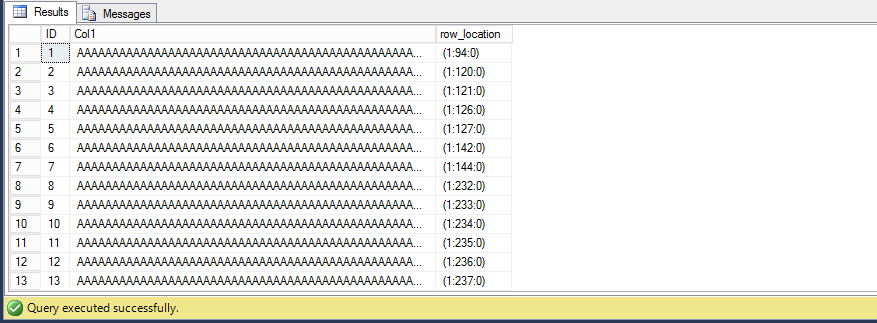
Every row we were inserting was (at the first thousand) getting a new page for itself and if we navigate till the end we can see how rows are consecutively placed one after another, because at the end of the day, that what a clustered index is.
Now have a look to the Heap:
SELECT * , sys.fn_PhysLocFormatter (%%physloc%%) AS row_location FROM dbo.heap_table
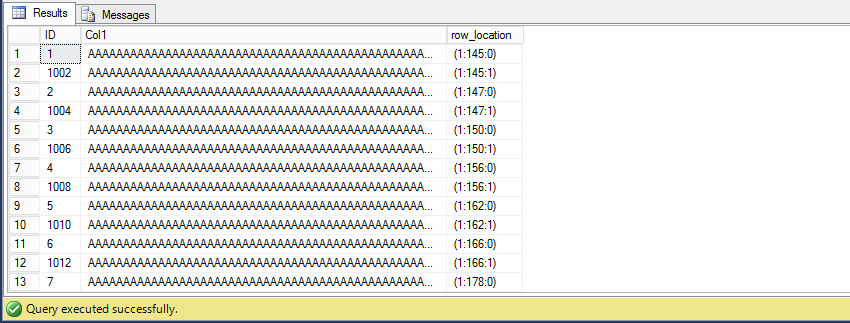
See how it’s true and the heap behaves completely different,
Id’s are completely scrambled. This is because new rows are not forced to occupy any specific place within the table, so they can freely go to whichever page, as far as there is enough free space for them to fit.
And that is how space can be reused for Heaps but not for clustered indexes.
Conclusion
We have seen that in general we should create our tables as Clustered index, but Heaps exist and can be useful in the right situation, and the case I exposed above well might be one of those special cases where it can make sense store our data in a Heap if we have storage constraints.
Obviously I wouldn’t recommend go wild and start dropping your clustered indexes to save a few bytes, you should deeply understand your data and how it is accessed before taking such decision.
And as always, thanks for reading and please ask any question you may have!
1 thought on “Successful Anti-Patterns, Storage Requirements”