The new In-Memory engine is now available on every edition of SQL Server, including Express, so there is no excuse to start exploring this amazing feature Last week Microsoft has done it. The release of SQL Server 2016 SP1 is a game changer, most of the desired but sometimes prohibitive features from Enterprise Edition are now available on each edition of SQL Server, including Express Edition. You can find more information about it here
One of the features I’m more exited about is the In-Memory OLTP or memory optimized for what it represents, the future is now open to every SQL Server application (up to a point).
So I really think it’s high time to start planning ahead and foresee all the incoming work either creating new databases or upgrading existing ones to take advantage of this feature, hence I’ll try to learn as much as possible and write and explain what I find most interesting.
Changes in the Storage Engine
One of the first things that is really cool it’s that Memory Optimized tables’ storage engine has been written to fulfil all the new expectations like no locks and latches and therefore rows are no longer stored in pages which belong to extents, that will still apply to disk-based tables.
For the new In-Memory engine, rows are stored individually in memory and are linked to other rows within the same table by pointers in an index chain.
To accomplish that we can see in books online that they have a completely new row structure which looks like this

Together with the new structure we can find new exciting surprises, to see how different they are, let me jump to write some code. I will use the new sample database [WideWorldImporters].
USE [WideWorldImporters] GO CREATE TABLE [Warehouse].[VehicleTemperatures_DiskBased]( [VehicleTemperatureID] [bigint] IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [VehicleRegistration] [nvarchar](20) COLLATE Latin1_General_CI_AS NOT NULL, [ChillerSensorNumber] [int] NOT NULL, [RecordedWhen] [datetime2](7) NOT NULL, [Temperature] [decimal](10, 2) NOT NULL, [FullSensorData] [nvarchar](1000) COLLATE Latin1_General_CI_AS NULL, [IsCompressed] [bit] NOT NULL, [CompressedSensorData] [varbinary](max) NULL) GO SET IDENTITY_INSERT [Warehouse].[VehicleTemperatures_DiskBased] ON INSERT INTO [Warehouse].[VehicleTemperatures_DiskBased] (VehicleTemperatureID, VehicleRegistration, ChillerSensorNumber, RecordedWhen, Temperature, FullSensorData, IsCompressed, CompressedSensorData) SELECT VehicleTemperatureID, VehicleRegistration, ChillerSensorNumber, RecordedWhen, Temperature, FullSensorData, IsCompressed, CompressedSensorData FROM [Warehouse].[VehicleTemperatures] SET IDENTITY_INSERT [Warehouse].[VehicleTemperatures_DiskBased] OFF GO
Changes in non clustered indexes
What I’ve done so far is I created a new table similar to an existing In-Memory and loaded it with the same rows, so we have 2 versions, In-Memory and Disk-Based, of the same table.
Now we are going to create a non-clustered index on both, please note that in SQL 2014 adding a new index would involve to DROP and re CREATE the table again, but I’m on SQL 2016 for good.
ALTER TABLE [Warehouse].[VehicleTemperatures] ADD INDEX IX_VehicleRegistration NONCLUSTERED (VehicleRegistration) GO CREATE NONCLUSTERED INDEX IX_VehicleRegistration_DiskBased ON [Warehouse].[VehicleTemperatures_DiskBased] (VehicleRegistration) GO
We can notice that the syntax differs from disk-based to In-Memory, but that’s not the best part.
If now I ask you what the typical query plan for a simple query to retrieve all the columns and filters on the column we just created our non-clustered index would be, good part of you will know the answer by heart.
And that will be either “Index seek + Lookup” or “Table Scan”, am I right? … I knew it!
Let’s then run it for both tables and check the query plans!
SELECT * FROM [Warehouse].[VehicleTemperatures_DiskBased] WHERE VehicleRegistration = 'xxxx' SELECT * FROM [Warehouse].[VehicleTemperatures] WHERE VehicleRegistration = 'xxxx'
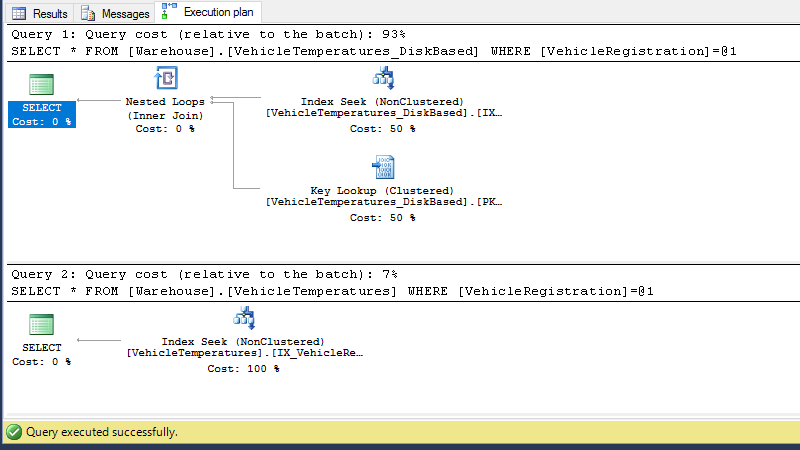
Wow, what happened there? This is something new I wasn’t expecting.
The first query matches one of our expected query plans, “Index Seek + Lookup” but just an “Index seek” doesn’t make sense, or it does?
What’s new and why it’s cool
Probably you have already realised that along the new row structure, Non Clustered indexes have also changed, for In-Memory I mean.
Non clustered indexes do not store data at the leaf level anymore, because the leaf level of the tree (now BwTree) now have pointers to the actual rows, and each row contains a pointer to the next row for each index defined on that table.
Get back to the row structure and check all those “Pointer Index 1”. Those are added for each index defined on our table to create the index chain.
That is totally cool, because it means there is no duplication of data and there is no need to include any column because they all are implicitly included as it’s the row itself.
No need for lookups anymore, awesome.
Conclusion
As I said, I believe Microsoft has done a good job by opening this technology to all available editions, because that will mean you no longer have to pay Enterprise Edition unless your workloads are big enough to justify it.
Also for all of us is really good, I have always looked at this thinking that not much people would be using it due to licensing and migration cost, but now there are no excuses.
This is just the beginning, I’ll keep playing with this and keep you posted.
Thanks for reading.
1 thought on “In-Memory NonClustered Indexes, much cooler than disk based”