From time to time it’s good to remind people about the complexity of a product such as SQL Server. The internals are so wide and complex that we easily get lost and follow what remains easier in our minds, rather than understanding the whole picture. From time to time it’s good to remind people about the complexity of a product such as SQL Server. The internals are so wide and complex that we easily get lost and follow what remains easier in our minds, rather than understanding the whole picture.
In this case I’ll present you with some benefits you may encounter by not following best practices, no need to say I’ll show you how to achieve the same by following best practices too. Tricky, isn’t it?
Background
Back in the day, someone decided it was a great idea (note the irony) to allow people to store any kind of data within a database, and that included ‘unlimited’ text and binary objects (images for instance) up to 2GB, so TEXT, NTEXT and IMAGE were added to SQL Server as data types.
Then things got a bit modern and those were replaced by VARCHAR(MAX), NVARCHAR(MAX) and VARBINARY(MAX) and the previous were marked as ‘Deprecated’ which means probably not much since at the moment of writing they’re still there.
Real case scenario
I have databases, like any good DBA, and some are full of XML documents stored as [N]TEXT. Some are really big tables, let me show you.
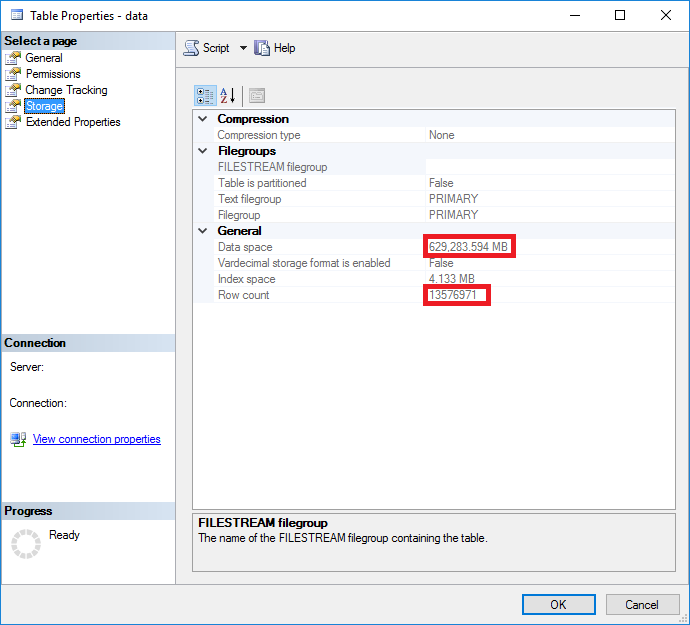
So a table with 13576971 rows and 629,398MB which are XML documents, not bad… We know already that SQL Server stores data within 8kb pages so approximately this table uses 80548829 pages.
This table contains a few columns with metadata that helps locating the xml document, so if we query the table to get all documents that match certain condition (there is no indexes on that column) we will have to scan the whole table to retrieve those documents.
The following query does not retrieve any row, since the created date cannot be greater than today.
USE [my_database] GO SET STATISTICS IO ON GO SELECT * FROM dbo.data WHERE created > DATEADD(DAY, 1, GETDATE()) GO
And as expected, we get the table scan to satisfy the query.
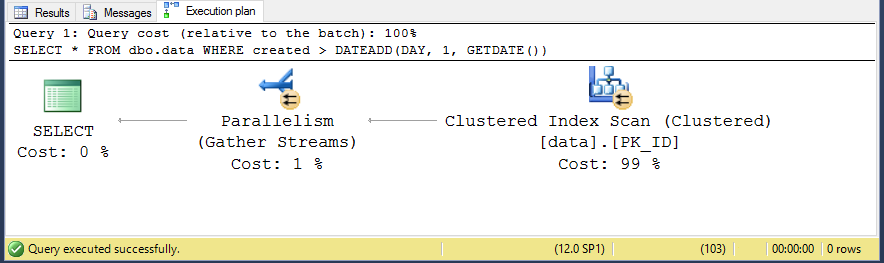
All good then, so we have to scan the clustered index (table) so we can assume the number of pages read will be certainly close to the 80,5M pages we have seen earlier, right?
Let’s check the ‘Messages’ tab.
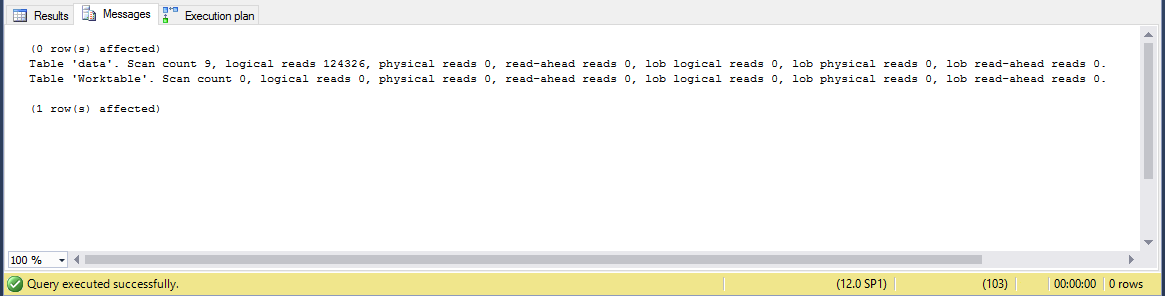
Hm? Only 125k? How come?
Explanation
We said data in SQL Server is stored in 8k pages, but these pages are managed in one or more allocation units depending on the data types.
If we have a look at Books online, we see that the different allocation unit types are
- IN_ROW_DATA, which contains all data excepts LOB data
- LOB_DATA, where LOB data types are stored (text, ntext, image, xml, and MAX data types)
- ROW_OVERFLOW_DATA, variable length data (not BLOBs) can sometimes end up here where the total length exceeds 8060 bytes row limit
So to see the data distribution in more detail, we need to split the total by allocation unit type.
SELECT OBJECT_NAME(ix.object_id)
, ix.name
, au.*
, p.rows
FROM sys.indexes AS ix
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
WHERE ix.object_id IN (OBJECT_ID('dbo.Data'))

We can see that our table is managed by two different allocation units, IN_ROW_DATA and LOB_DATA, which means that all data within columns of the data types above, will end up in different pages by default, regardless of the size of the data.
This is the default behaviour for old LOB types, to be stored separately, but new LOB types (MAX) by default will try to get them In-Row if they are small enough to fit.
Having some of those documents In-Row will result in a serious increase in the number of pages to scan, therefore affecting performance.
Note that for the table scan we have used only the IN_ROW_DATA pages, making it much lighter than if we have to scan the sum of all pages.
The new way of doing things
As I said, we can achieve the same behaviour using the new (MAX) data types using the stored procedure sp_tableoption by specifying ‘large value types out of row’ option to be true.
This SP will work to make deprecated data types to behave like new ones too by specifying a value between 24 and 7000 for the option ‘text in row’.
So we are in total control of where our LOB data happen to be stored, to match our usage pattern.
Conclusion
Off the shelf, SQL Server works with default settings and the same we change server and database settings for several reasons, being able to decide where our data will be stored opens plenty of possibilities to better manage it and get the best performance for our queries.
In this case using the deprecated data types has given us (because of the default storage) some serious benefit when it’s time to scan a big table like this, but the same can be accomplished tweaking the new data types, so there is no real need to keep using the old data types.
There are some links I don’t want to end without sharing them.
- Table and Index Organization
- In-Row Data
- Row-Overflow Data Exceeding 8 KB
- sp_tableoption
- Importance of choosing the right LOB storage technique
Thanks for reading!
You should mention the drawback on this behavior.
When you have a table with e.g. 5 varchar(max) data types and each (in every row of the table) contains usually only up to 50 chars (e.g. comment fields, that COULD be big but will be usually very short), it would take some additional reads, when you select a row by its primary key. For single reads it would be regardless, but sometimes you have a query with nested loops, where it will blow up your total read pages count, when even the shortest comment will be stored in the LOB-pages.
Thanks for your comment!
You’re right, there are benefits and drawbacks, the important thing is to know how the data will be accessed.
If you need, for instance, to filter on those columns, accessing each document for a table scan will be very expensive.
You can think of it like if you have to tables (vertical partitioning, from Paul Randal’s link) as far as you access the “metadata” and not multiple documents at a time, you’re better off with either 2 tables or Off-Row storage, otherwise, yes, you probably get better performance using In-Row,
Like always, it depends. Cheers.