Compression in SQL Server has been around for a while now, come explore how it works internally Compression in SQL Server has been around for a while now, to be precise since SQL Server 2008, and comes in two different (complementary) flavors, ROW and PAGE compression. Unfortunately it’s only available in the Enterprise Edition (and Developer per instance).
This article is not a substitute for the in-depth knowledge you can get by reading the whitepaper and other reputable sources, consider it just a teaser for you to go back and play a bit with this interesting feature.
The compression I want to focus this writing is ROW compression, which is the first step in SQL Server native compression, where all columns in a table where is applied behave as if all datatypes were variable length (if possible).
That is totally cool, since you know that a variable length column will use only as much storage as required up to the maximum length defined for the column (see VARCHAR as example).
This same behavior will apply for all those data types which are fixed length and may result in a good deal of storage savings at the end of the day. (If the data stored in them do not require all storage, of course)
ROW compression reduces also the metadata overhead for each row, so we’d be able to save a few bytes there too.
To see how differently the data is physically stored in the pages, I’ve created this demo
USE master
GO
IF DB_ID('compressiontestdb') IS NOT NULL BEGIN
ALTER DATABASE [compressiontestdb] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [compressiontestdb]
END
GO
CREATE DATABASE [compressiontestdb]
GO
USE compressiontestdb
GO
IF OBJECT_ID('dbo.no_compressed_data') IS NOT NULL DROP TABLE dbo.no_compressed_data
IF OBJECT_ID('dbo.compressed_data') IS NOT NULL DROP TABLE dbo.compressed_data
GO
CREATE TABLE dbo.no_compressed_data(
Id BIGINT IDENTITY(1,1) NOT NULL,
Col2 INT NOT NULL ,
Col3 INT NOT NULL ,
Col4 SMALLINT NOT NULL,
PRIMARY KEY (Id)
)
GO
CREATE TABLE dbo.compressed_data(
Id BIGINT IDENTITY(1,1) NOT NULL,
Col2 INT NOT NULL ,
Col3 INT NOT NULL ,
Col4 SMALLINT NOT NULL,
PRIMARY KEY (Id) WITH (DATA_COMPRESSION=ROW)
)
GO
INSERT INTO dbo.no_compressed_data
SELECT 2,3,4
FROM sys.objects AS o1
CROSS APPLY sys.objects AS o2
INSERT INTO dbo.compressed_data
SELECT Col2
, Col3
, Col4
FROM dbo.no_compressed_data
-- See list of pages allocated to the cluestered index of each table
DBCC IND('compressiontestdb', 'dbo.no_compressed_data', 1)
DBCC IND('compressiontestdb', 'dbo.compressed_data', 1)
GO
-- First glance, Compressed table has half of the pages / hence the size, good gain
DBCC TRACEON(3604,1)
-- No Compression
-- Use first page with PageType = 1
DBCC PAGE('compressiontestdb', 1, 119, 3)
-- Row Compression
-- Use first page with PageType = 1
DBCC PAGE('compressiontestdb', 1, 147, 3)
The first impression is good, DBCC IND returned half the pages for the compressed version of the table, so it’s half the size… that’s what we talkin’ about!
If we go deeper and see the header of the first page of each clustered index, we can see how many rows fit in a single page with and without compression

We fit 736 compressed rows versus 299 rows without compression, not bad at all. Obviously those ratios may vary depending on the data we store, the smaller the data comparing to the fixed length data type, the more gain we get.
If we compare row to row we can see how different they got to the data pages.
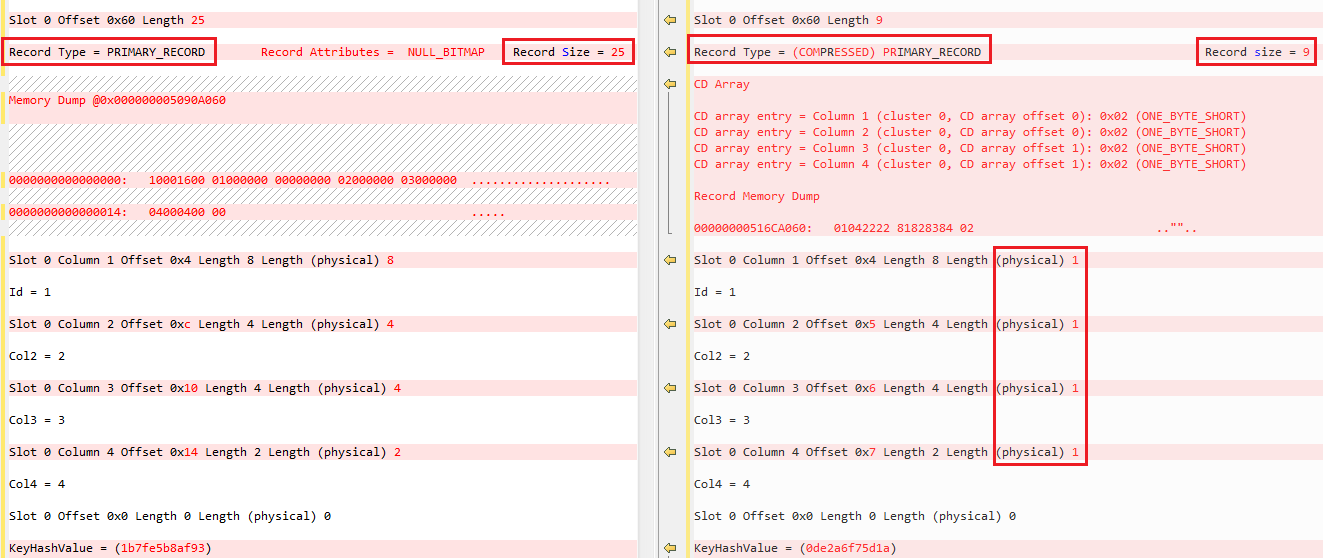
On the left side, we can see the data as is, where each value take as much space as its data type is supposed to, but on the right we see that the physical storage is the minimum to hold the value, so if it is a number which fit in one byte, it physically takes one byte, regardless it’s a SMALLINT(2 bytes), INT (4 bytes) or BIGINT(8 bytes)
But even if we push the data to the boundaries of the data type, we still might get some benefit, not much, but some.
USE master
GO
IF DB_ID('compressiontestdb') IS NOT NULL BEGIN
ALTER DATABASE [compressiontestdb] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [compressiontestdb]
END
GO
CREATE DATABASE [compressiontestdb]
GO
USE compressiontestdb
GO
IF OBJECT_ID('dbo.no_compressed_data') IS NOT NULL DROP TABLE dbo.no_compressed_data
IF OBJECT_ID('dbo.compressed_data') IS NOT NULL DROP TABLE dbo.compressed_data
GO
CREATE TABLE dbo.no_compressed_data(
Id INT IDENTITY(1000000000,1) NOT NULL,
Col2 INT NOT NULL ,
Col3 INT NOT NULL ,
Col4 SMALLINT NOT NULL,
PRIMARY KEY (Id)
)
GO
CREATE TABLE dbo.compressed_data(
Id INT IDENTITY(1000000000,1) NOT NULL,
Col2 INT NOT NULL ,
Col3 INT NOT NULL ,
Col4 SMALLINT NOT NULL,
PRIMARY KEY (Id) WITH (DATA_COMPRESSION=ROW)
)
GO
INSERT INTO dbo.no_compressed_data
SELECT 1000000000,1000000000,32000
FROM sys.objects AS o1
CROSS APPLY sys.objects AS o2
INSERT INTO dbo.compressed_data
SELECT Col2
, Col3
, Col4
FROM dbo.no_compressed_data
-- See list of pages allocated to the cluestered index of each table
DBCC IND('compressiontestdb', 'dbo.no_compressed_data', 1)
DBCC IND('compressiontestdb', 'dbo.compressed_data', 1)
GO
DBCC TRACEON(3604,1)
-- No Compression
DBCC PAGE('compressiontestdb', 1, 178, 3)
-- Row Compression
DBCC PAGE('compressiontestdb', 1, 191, 3)
24 pages for not compressed data versus 21, you can see by yourselves the different way of storing the data. Different row size because of the metadata.
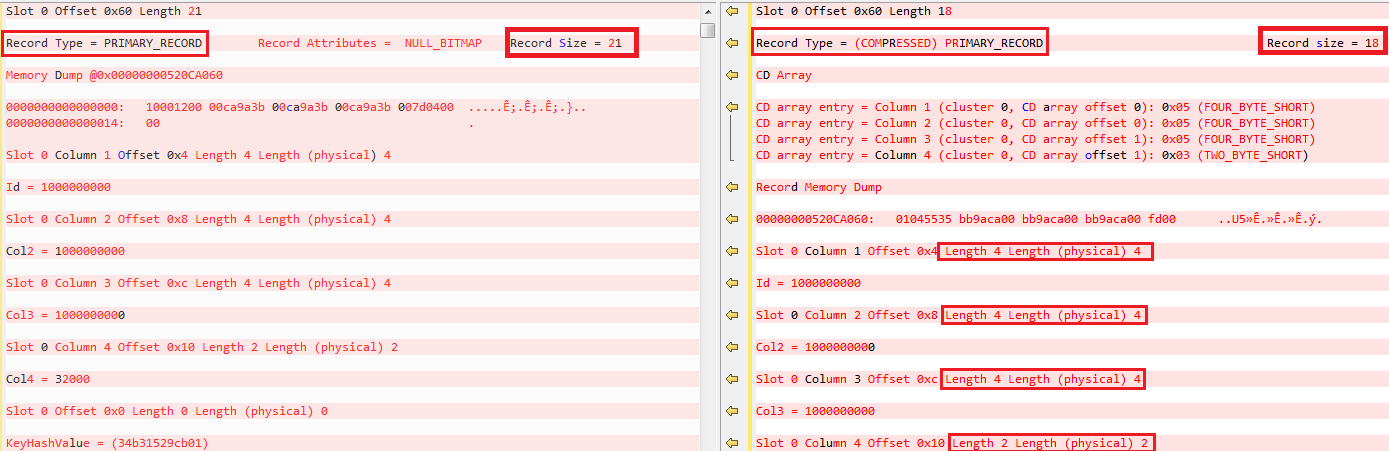
UNICODE compression
Another important gain will be in case you need to store a mix of UNICODE and not UNICODE values, and therefore you have defined a column as NVARCHAR(NOT MAX). In that case, if you apply compression, the non UNICODE characters will take 1 byte and not 2 as UNICODE does, so that overhead will be use in case is strictly necessary.
This point is not very clear when you read Books Online, as depending on the version you read, is correct or not.
Correct
https://technet.microsoft.com/en-us/library/cc280576(v=sql.105).aspx
Wrong
https://technet.microsoft.com/en-us/library/cc280576(v=sql.110).aspx
You can see that this was an improvement that started to apply in SQL Server 2008R2, not in 2008 as compression itself.
You can see how UNICODE compression applies in the following example
USE master
GO
IF DB_ID('compressiontestdb') IS NOT NULL BEGIN
ALTER DATABASE [compressiontestdb] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [compressiontestdb]
END
GO
CREATE DATABASE [compressiontestdb]
GO
USE compressiontestdb
GO
IF OBJECT_ID('dbo.no_compressed_data') IS NOT NULL DROP TABLE dbo.no_compressed_data
IF OBJECT_ID('dbo.compressed_data') IS NOT NULL DROP TABLE dbo.compressed_data
GO
CREATE TABLE dbo.no_compressed_data(
Id INT IDENTITY(1000000000,1) NOT NULL,
Col2 INT NOT NULL ,
Col3 INT NOT NULL ,
Col4 NVARCHAR(200) NULL,
PRIMARY KEY (Id)
)
GO
CREATE TABLE dbo.compressed_data(
Id INT IDENTITY(1000000000,1) NOT NULL,
Col2 INT NOT NULL ,
Col3 INT NOT NULL ,
Col4 NVARCHAR(200) NULL,
PRIMARY KEY (Id) WITH (DATA_COMPRESSION=ROW)
)
GO
INSERT INTO dbo.no_compressed_data
SELECT 1000000000,32000, REPLICATE(N'A', 200)
FROM sys.objects AS o1
CROSS APPLY sys.objects AS o2
INSERT INTO dbo.compressed_data
SELECT Col2
, Col3
, Col4
FROM dbo.no_compressed_data
-- See list of pages allocated to the cluestered index of each table
DBCC IND('compressiontestdb', 'dbo.no_compressed_data', 1)
DBCC IND('compressiontestdb', 'dbo.compressed_data', 1)
GO
DBCC TRACEON(3604,1)
-- No Compression
DBCC PAGE('compressiontestdb', 1, 119, 3)
-- Row Compression
DBCC PAGE('compressiontestdb', 1, 147, 3)
See how compression do the job here
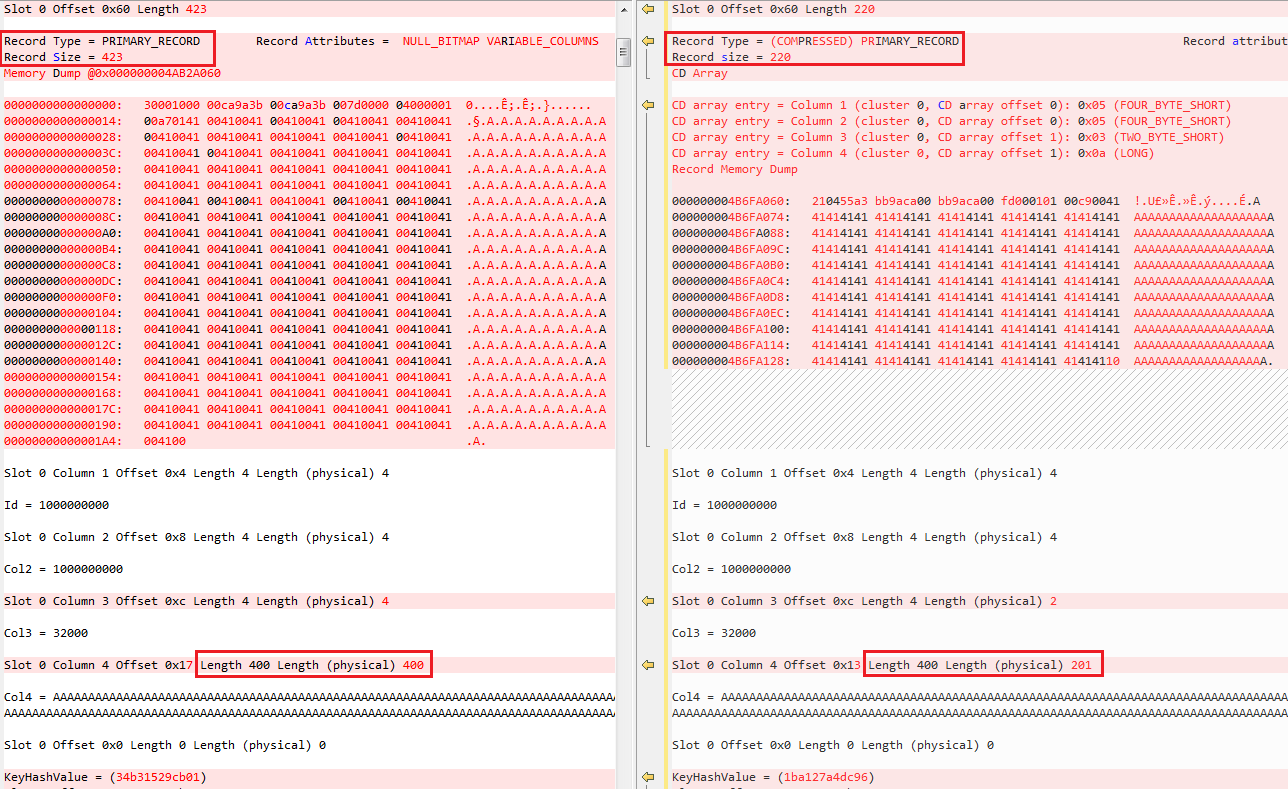
And remember UNICODE compression only applies for non LOB columns (that excludes NVARCHAR(MAX) too).
USE master
GO
IF DB_ID('compressiontestdb') IS NOT NULL BEGIN
ALTER DATABASE [compressiontestdb] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [compressiontestdb]
END
GO
CREATE DATABASE [compressiontestdb]
GO
USE compressiontestdb
GO
IF OBJECT_ID('dbo.no_compressed_data') IS NOT NULL DROP TABLE dbo.no_compressed_data
IF OBJECT_ID('dbo.compressed_data') IS NOT NULL DROP TABLE dbo.compressed_data
GO
CREATE TABLE dbo.no_compressed_data(
Id INT IDENTITY(1000000000,1) NOT NULL,
Col2 INT NOT NULL ,
Col3 INT NOT NULL ,
Col4 NVARCHAR(MAX) NULL,
PRIMARY KEY (Id)
)
GO
CREATE TABLE dbo.compressed_data(
Id INT IDENTITY(1000000000,1) NOT NULL,
Col2 INT NOT NULL ,
Col3 INT NOT NULL ,
Col4 NVARCHAR(MAX) NULL,
PRIMARY KEY (Id) WITH (DATA_COMPRESSION=ROW)
)
GO
INSERT INTO dbo.no_compressed_data
SELECT 1000000000,32000, REPLICATE(N'A', 200)
FROM sys.objects AS o1
CROSS APPLY sys.objects AS o2
INSERT INTO dbo.compressed_data
SELECT Col2
, Col3
, Col4
FROM dbo.no_compressed_data
-- See list of pages allocated to the cluestered index of each table
DBCC IND('compressiontestdb', 'dbo.no_compressed_data', 1)
DBCC IND('compressiontestdb', 'dbo.compressed_data', 1)
GO
DBCC TRACEON(3604,1)
-- No Compression
DBCC PAGE('compressiontestdb', 1, 119, 3)
-- Row Compression
DBCC PAGE('compressiontestdb', 1, 147, 3)
In this case the result is that no compression can apply.
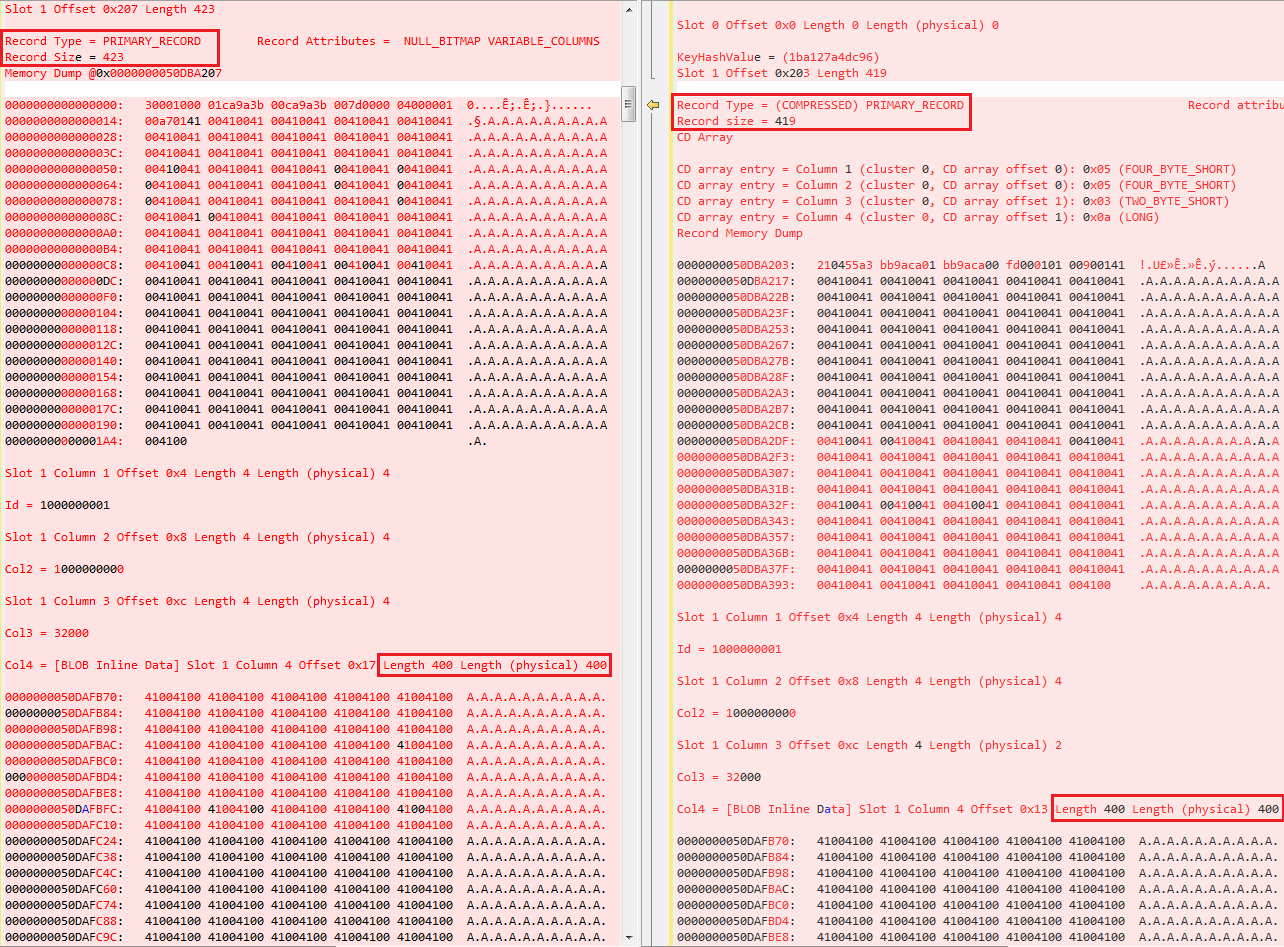
Hope you enjoyed the reading and now feel more curious about all these internals.