Sometimes things are not exactly how we think they are. Read the story of the missing default value and learn why. *First published @ www.SQLServerCentral.com (2015/12/01)
Once upon a time, there was a DBA… yeah right!
As probably like many SQL DBA’s, little by little I’m getting more curious about how SQL Server works internally. To learn more, I’m using a variety of resources, books, blog posts and more. An important part of internals is the SQL Server storage engine and one of the first things you need to know is how SQL Server stores the data.
First, I have to say I’m not claiming to be an expert, and I don’t pretend to speak like one of them. I hope this story can come across to regular people who want to learn about something curious maybe you have never thought of before.
Background
Not so long ago I had to add one column to a table (What a challenge for a DBA!!), but the table I had to deal with was a terrible, 120 million row table. Does that sound more like a challenge?
The column was just a flag (bit), to facilitate some logic when accessing the table. This would also allow us to create some filtered indexes. I wanted the field to be NOT NULL and to have a DEFAULT VALUE of 0.
First idea, easy peasy, just write the command and you’re good to go.
ALTER TABLE dbo.MyTable ADD Flag BIT NOT NULL CONSTRAINT DF_MyTable_Flag_0 DEFAULT 0
It’s important to mention this happened on a SQL Server 2008R2 instance, which probably lots of people are still running.
When running this statement, I had time to go for coffee, returning to find it was still running on my DEV box.
OK, that’s something I don’t want to happen. The table was locked and no one could access it. This might not a big deal in a DEV environment, but a big problem in production (24×7), where people are trying to access the table constantly.
According to Books online,
The Database Engine uses schema modification (Sch-M) locks during a table data definition language (DDL) operation, such as adding a column or dropping a table. During the time that it is held, the Sch-M lock prevents concurrent access to the table. This means the Sch-M lock blocks all outside operations until the lock is released.
When you have millions of rows to update, writing the simplest and cheapest value (1 byte), will become really expensive. For many minutes your table will be locked and users will be waiting to access the data.
So my idea of defining the column properly (in terms of nullability and default value) got to a point where I had to choose between my users or my ego. Since I can’t have people waiting for something like this, the choice was clear.
I worked around this issue by creating the column as NULL, updating the values to 0 in small batches, and that was it. The job was completed without locking problems.
OK, but what about the mysterious default value? Ups, I almost forgot. 🙂
Up to SQL Server 2008R2, when we add a column to a table that contains rows, the metadata is updated, the new column is added to the table, the default constraint is created and every single row within the table is UPDATED to hold the new value, not necessarily in that order.
We can see how it happens in this demo.
Create the playground (SQL Server 2008R2)
We need to create one table and insert some values.
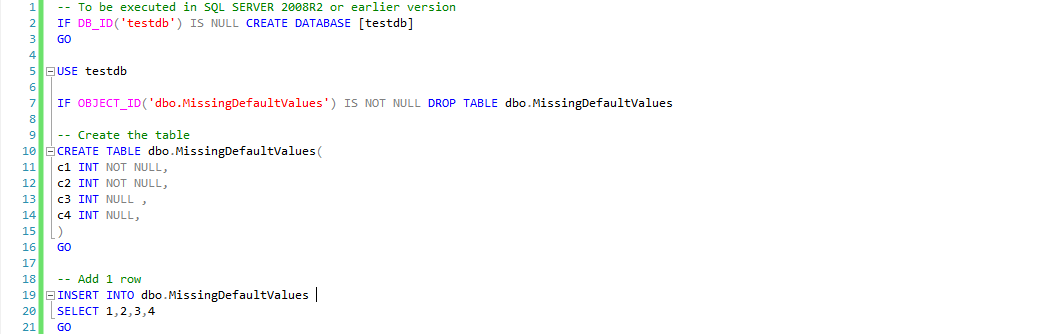
Now let’s see how this row looks like in a data page. You can use the undocumented unsupported commands DBCC IND() and DBCC PAGE(), the first to get a list of pages that belong to my index table and the second to dump the content of one of the pages to my messages tab in SSMS.
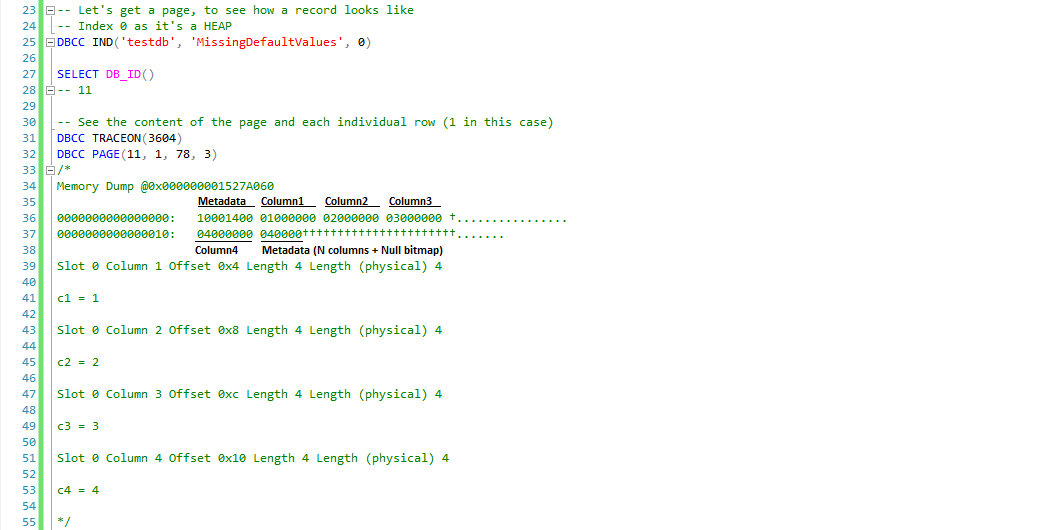
If we look at it, we see the first four bytes belong to metadata (I won’t go into it further, though I’d suggest further reading on this), then we can see the values corresponding to our four columns
• 01000000 is column c1 value 1
• 02000000 is column c2 value 2
• 03000000 is column c3 value 3
• 04000000 is column c4 value 4
• 040000, the last 3 bytes, the first two belong to the number of columns and the third one to the NULL bitmap
Also we can see how a value stored as INT datatype takes 4 bytes (as expected).
Now if we add our column the way we want, NOT NULL WITH VALUES, we will see how this change is reflected to the data pages.
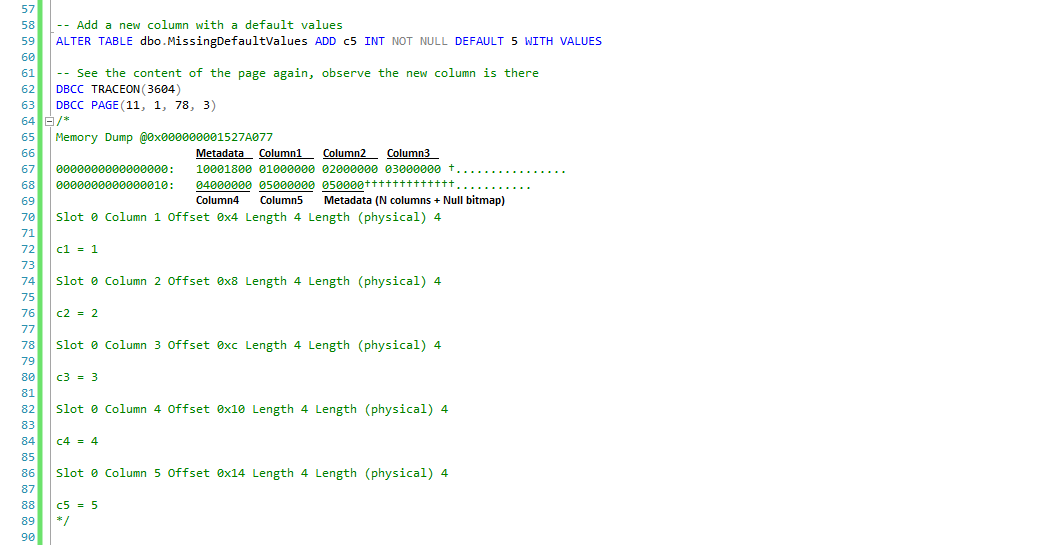
The new column is added after the existing one, and the new value is written. See that 05000000 is column c5 value 5, and the number of columns is updated to five.
This happened immediately because we had a single row in our table, but let’s see how this works when we have a large number of rows involved.
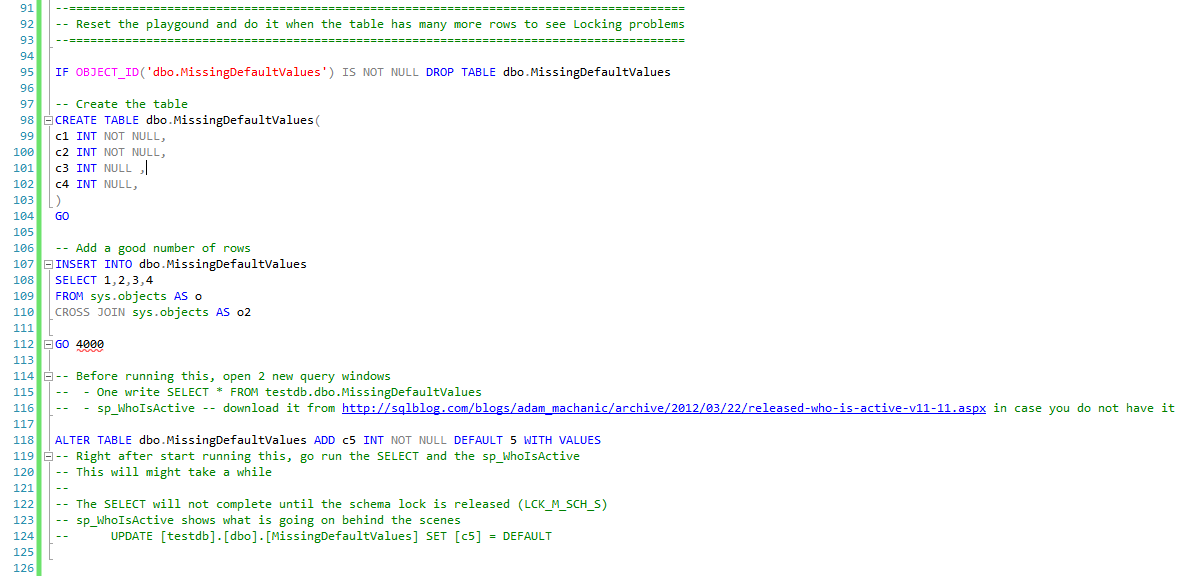
In one of the other windows, we execute a SELECT against our table:

And execute sp_WhoIsActive to see what is going on:

So for each row in the table, SQL Server actually write the value (see the UPDATE without a WHERE clause). That’s why it takes so long to execute and prevents any other request to access the table)
OK, but what about the mysterious default value?
It seems like the SQL Server team has been working hard since this process, adding a NOT NULL column WITH VALUES, has become a much less painful process. I will demo it for you.
If I say the same statement will take practically no time even when the table contains millions of rows, would you believe me? OK, get ready for what you’re going to see. This will run in a SQL Server 2012+ instance.
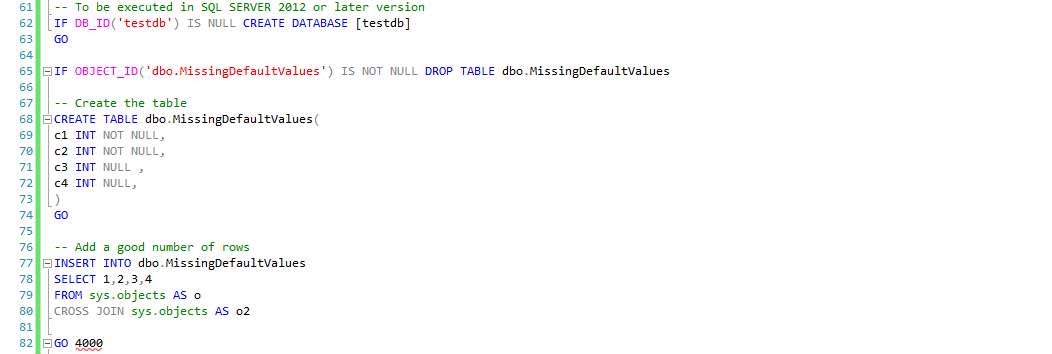
Create the playground (SQL2012 onwards)
We create the same table and insert a large amount of rows as we did back in SQL2008R2.
Previously we have seen that when we create a new column with a default constraint WITH VALUES, SQL Server had to write those values for each row. We also saw how they are stored on each page for that table.
Let’s give it a go.

Wow, that was quick! But wait… Maybe it didn’t finish properly…
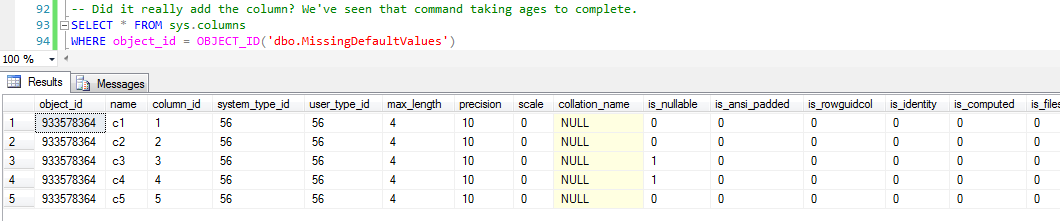
Ok, the column is there, and so are the values. Let’s have a look at one of the pages to see one row. We’ve seen that specifying the last parameter as 3 in DBCC PAGE() will output each row individually together with each column and value.
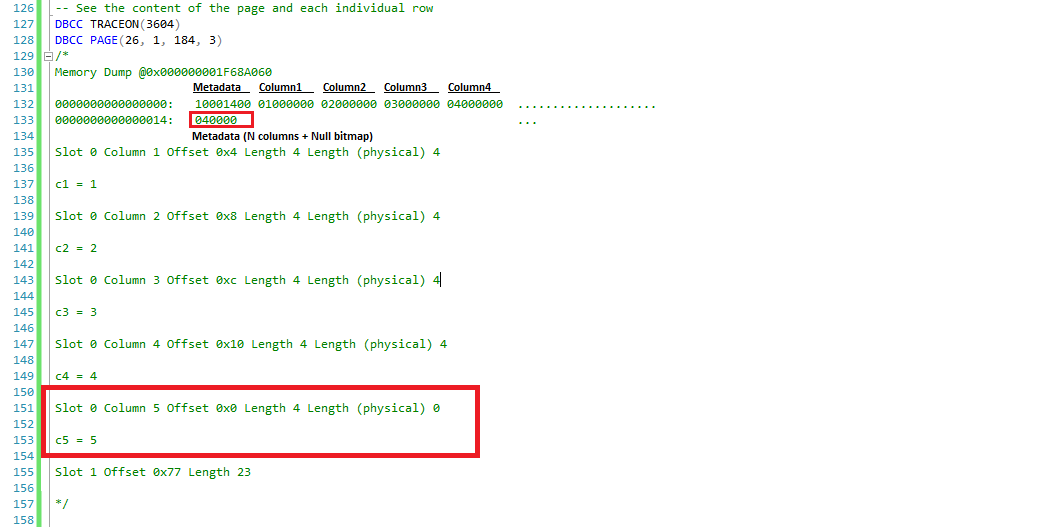
Errrr, where is the DATA? The row does not have the value on it, but we can see in the detail for each row that c5 = 5. Note also that the column count at the end of the row does not match, still shows 4 (0x0400).
Run again both statements and rub your eyes, the SELECT and DBCC PAGE bring up the column and its value but they actually DO NOT exist in the page, everything is a metadata illusion.
The Metadata
The metadata associated to this new column is as follows. First, the SQL engine knows there is a new column.
And it’s aware of the Default constraint definition.

So technically the SQL engine does not care whether the value is stored along with the other values in each row within a data page as long as it knows what the value should be like.
What if we UPDATE some of the rows?

After updating some rows we can see that those rows updated do have the value now (** Note I’m updating c1, nothing to do with c5).
SQL Server knows there is something not quite consistent and it does the job any other time it’s got to go there to update something else… Smart!
Conclusion
The change of behaviour explained is a major improvement and can save a lot of grief for DBAs.The actual work can happen at other more convenient time since the final output can rely exclusively on the column’s metadata. This avoids long term SCHema Modification Locks required by ALTER TABLE that prevent other people from accessing the data.
So seems like we’ve solved the mystery of the missing default value, but wait… where is record 10?
That’s another story my friends but don’t worry, one of these days I will tell you about the “Mystery of the 10th record”.
Hope you have enjoyed the reading, just to finish I want to put together all references and concepts involved in this article.
•ALTER TABLE ADD COLUMN and Default constraints
•Locking and blocking
•DBCC IND and DBCC PAGE
•Database structures, row structure
•sys.fn_PhysLocFormatter
•sp_whoIsActive
Just to say thanks to my friend and reviewer @jonwolds for his help.