More new functionalities coming along with SQL Server 2016, this time I’ve been playing with COMPRESS and DECOMPRESS One of the most exciting things for me in this new version of SQL Server is inclusion of native gzip compression into the, I guess, storage engine functionalities.
I know you can implement your own CLR version of it and so on, but for many people that is not a real possibility due to security concerns, lack of resources, knowledge or any other reason, that’s why for many this will be really good news.
I couldn’t find any reference to which SQL Server editions will have it, but I want to be optimistic and think it will be available at least in Standard Edition, as opposite as ROW and PAGE compression (Enterprise only)
One of the many use cases might be to compress big text columns, either VARCHAR(MAX) or NVARCHAR(MAX), since ROW and PAGE compression don’t quite work well on these data types.
Let’s see how much space we can save using a table from the sample database [AdventureWorks2016CTP3] on my shinny new SQL Server 2016 RC1 instance. I’ve chosen the table [Person].[Person] as base, since it’s one of the “big boys” (hm hm), but I have to convert from XML to NVARCHAR(MAX).
USE [AdventureWorks2016CTP3]
GO
DROP TABLE IF EXISTS [Person].[Person_nvarchar]
GO
-- Create table as NVARCHAR(MAX) from the originally XML columns
SELECT [BusinessEntityID]
,[PersonType]
,[NameStyle]
,[Title]
,[FirstName]
,[MiddleName]
,[LastName]
,[Suffix]
,[EmailPromotion]
,(CONVERT(NVARCHAR(MAX), [AdditionalContactInfo])) AS [AdditionalContactInfo]
,(CONVERT(NVARCHAR(MAX), [Demographics])) AS [Demographics]
,[rowguid]
,[ModifiedDate]
INTO [Person].[Person_nvarchar]
FROM [Person].[Person]
GO
CREATE UNIQUE CLUSTERED INDEX CIX_Person_nvarchar ON [Person].[Person_nvarchar] ([BusinessEntityID])
GO
USE [AdventureWorks2016CTP3]
GO
DROP TABLE IF EXISTS [Person].[Person_gzip]
GO
-- Create table with gzip compression on the originally XML columns
SELECT [BusinessEntityID]
,[PersonType]
,[NameStyle]
,[Title]
,[FirstName]
,[MiddleName]
,[LastName]
,[Suffix]
,[EmailPromotion]
,COMPRESS(CONVERT(NVARCHAR(MAX), [AdditionalContactInfo])) AS [AdditionalContactInfo]
,COMPRESS(CONVERT(NVARCHAR(MAX), [Demographics])) AS [Demographics]
,[rowguid]
,[ModifiedDate]
INTO [Person].[Person_gzip]
FROM [Person].[Person]
GO
CREATE UNIQUE CLUSTERED INDEX CIX_Person_gzip ON [Person].[Person_gzip] ([BusinessEntityID])
GO
Now we can see some numbers.
-- See numbers
SELECT OBJECT_SCHEMA_NAME(ix.object_id) AS [schema]
, OBJECT_NAME(ix.object_id) AS [object_name]
, p.rows AS [row_count]
, SUM(ps.used_page_count) AS [used_page_count]
FROM sys.indexes AS ix
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.dm_db_partition_stats AS ps
ON ps.partition_id = p.partition_id
WHERE ix.object_id IN (OBJECT_ID('Person.Person'), OBJECT_ID('Person.Person_gzip'), OBJECT_ID('Person.Person_nvarchar'))
GROUP BY ix.object_id, p.rows
ORDER BY [schema], [object_name]
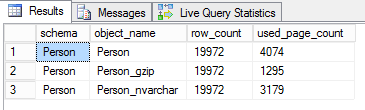
We can observe that the original table with the XML data types is the biggest, followed by NVARCHAR(MAX) and the winner is obviously COMPRESSED. So far it does what it says on the tin 🙂
But probably now, you’re ready to ask me the question I’ve been asked the most. What about performance?
The performance
Almost nothing in this life comes for free, so what is the penalty we have to pay for keeping our SAN admin happy? Let’s find it out with some queries.
First let’s go for a full table clustered index scan
USE [AdventureWorks2016CTP3] GO SET STATISTICS IO, TIME ON GO SELECT * FROM Person.Person --(19972 row(s) affected) --Table 'Person'. Scan count 1, logical reads 3838, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. -- SQL Server Execution Times: -- CPU time = 31 ms, elapsed time = 1318 ms. SELECT * FROM Person.Person_gzip --(19972 row(s) affected) --Table 'Person_gzip'. Scan count 1, logical reads 1290, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. -- SQL Server Execution Times: -- CPU time = 47 ms, elapsed time = 430 ms. SELECT * FROM Person.Person_nvarchar --(19972 row(s) affected) --Table 'Person_nvarchar'. Scan count 1, logical reads 3173, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. -- SQL Server Execution Times: -- CPU time = 46 ms, elapsed time = 600 ms.
And once again, when doing a full scan, the victory is for the smallest table, hence the result is the same, XML, NVARCHAR(MAX), COMPRESSED. That is reasonable, the less you read, the faster you finish.
But there must be some caveats round the corner, it can’t be all benefit.
For this query I’ll leave out of the equation the original table as XML cannot be queried as normal string and I feel lazy to write xquery now 🙂
I’m going to try find all married people, and I’ve seen there is an attribute in the XML that contains that info, I’d query it as a string just for demonstration purposes, do not take this as best practice, if you need to query XML, be sure you use XML data type and xquery (combined with XML indexes for best performance)
-- if we look for a value within the compressed column SELECT CAST(DECOMPRESS(Demographics) AS NVARCHAR(MAX)), * FROM Person.Person_gzip WHERE CAST(DECOMPRESS(Demographics) AS NVARCHAR(MAX)) LIKE '%<MaritalStatus>M%' -- same search within the nvarchar column SELECT * FROM Person.Person_nvarchar WHERE Demographics LIKE '%<MaritalStatus>M%'
And here is the penalty
/* SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (10011 row(s) affected) Table 'Person_gzip'. Scan count 1, logical reads 1289, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 1812 ms, elapsed time = 2958 ms. (10011 row(s) affected) Table 'Person_nvarchar'. Scan count 1, logical reads 3173, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 282 ms, elapsed time = 992 ms. */
Decompressing each value to find something is not that cheap anymore. After many runs I can see that consistently takes about 3 times the total time and about 5 times the CPU time than if you don’t have to decompress it.
Conclusion
COMPRESS is a nice feature, but be sure that fits your use case, because trying to save in storage can impact the overall performance very badly.
1 thought on “SQL Server 2016 COMPRESS and DECOMPRESS performance”