Having statistics up to date is important to get good query plans, but sometimes how to get it might be misunderstood On the 15th of June I made my first presentation at my local user group, and I have to say that was a nice experience.
The presentation is about SQL Server statistics and at certain point one of the users raised that you can get away without updating stats because all of them will get updated when you rebuild your clustered Index.
This statement has some truth and some misconception altogether, because there are different kind of statistics, some are strictly associated to an Index (clustered or non-clustered) and others associated to one or more columns in a table.
But let’s see an specific example on our [AdventureWorks2014] database.
USE AdventureWorks2014
GO
SELECT OBJECT_NAME(st.object_id)
, st.name
, stp.last_updated
, st.auto_created
FROM sys.stats AS st
CROSS APPLY sys.dm_db_stats_properties(st.object_id, st.stats_id) AS stp
WHERE st.object_id = OBJECT_ID('Sales.SalesOrderDetail')
GO
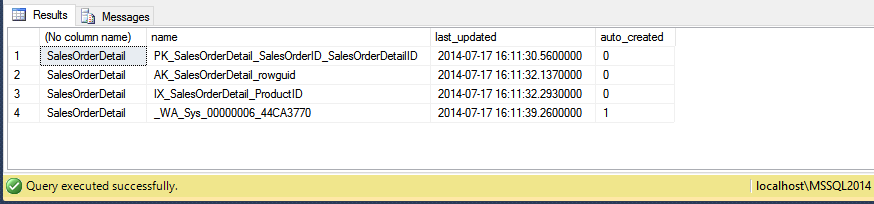
So, you can see for our table we have four different statistics, three of them are named after the index that created them (also are flagged as auto_created = 0) and the last one has this funny name and is flagged as auto_created = 1.
The latter is a column statistics and SQL Server was the one who decided that it’s a good idea to get some knowledge about the insights of the data stored within that column and did create them.
The misconception is that if we rebuild the clustered index, all statistics associated to our table will be automatically updated. Which is not true and we are going to prove it!
USE AdventureWorks2014
GO
ALTER INDEX [PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID] ON [Sales].[SalesOrderDetail] REBUILD
GO
SELECT OBJECT_NAME(st.object_id)
, st.name
, stp.last_updated
, st.auto_created
FROM sys.stats AS st
CROSS APPLY sys.dm_db_stats_properties(st.object_id, st.stats_id) AS stp
WHERE st.object_id = OBJECT_ID('Sales.SalesOrderDetail')
GO
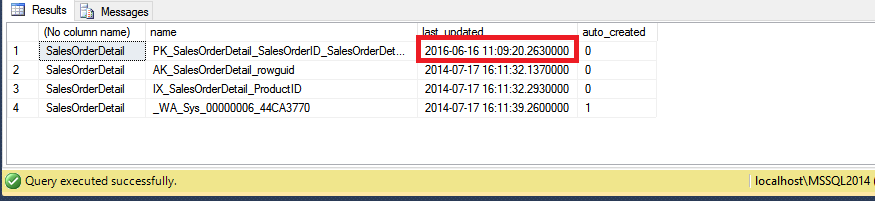
You can observe the only row which has changed is the one which matches with the index we have just rebuilt, no other statistics are touched.
The same would happen for any of the other indexes, so there won’t be a cascade of statistics updates triggered by any of them.
The good part is that the stats associated to the index we’ve just rebuilt, are updated as if we did UPDATE STATISTICS WITH FULLSCAN, so they are as accurate as they can be
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail', 'PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID') WITH STAT_HEADER

See how the number of rows sampled equals the total rows, so it can’t be any better.
Conclusion
I admit that it can make sense that column statistics were updated when the clustered index is rebuilt since we have touch the whole table, but the fact is that unfortunately we still have to keep an eye on our column statistics and see if they need to be updated from time to time (I mean, go and schedule it if you haven’t done it yet!), but hey! that sort of things pay our groceries 🙂