There has been a permanent debate about which is the right clustering key for our tables since the beginning of the time, this time I’ll get a bit deeper to show you the possible consequences of that choice There has been a permanent debate about which is the right clustering key for our tables since the beginning of the time, well the SQL Server time :), and repeating the same mantras are not going to add anything new, so I will not do it.
This post is more intended to show what happens when you choose a random value as the key for your clustered index from a much deeper angle.
Hopefully you will find very fascinating how the theoretical knowledge about SQL Server internals finally makes total sense.
Background
This far I assume, in general terms, everyone agrees that using a UNIQUEIDENTIFIER column as our clustered index key is bad, we’ve heard many times it will produce fragmentation and that’s really bad, so we tend not to although there might be some use cases (one of these days I’ll try write something).
But how does this happen and how bad is it? Well, that’s the fun part, so let’s get to it.
Preparing the playground
We’d need a new database and a new table with our bad practice ready to hit us.
CREATE DATABASE bad_cluster_key
GO
USE bad_cluster_key
GO
CREATE TABLE dbo.BadClusterKey(
ID UNIQUEIDENTIFIER NOT NULL CONSTRAINT PK_BadClusterKey PRIMARY KEY DEFAULT NEWID()
, Col1 CHAR(100) DEFAULT REPLICATE('A', 100)
, Col2 CHAR(100) DEFAULT REPLICATE('B', 100)
)
GO
INSERT INTO dbo.BadClusterKey DEFAULT VALUES
GO 1000
I’ve just created the table and done 1000 single INSERT, since the clustered key has a pretty random value returned by NEWID(), inserts have been occurring in random places all over our table (clustered index).
In order to remove the fragmentation we have, I’m going to rebuild it.
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('dbo.BadClusterKey'), NULL, NULL, 'DETAILED')
-- 41 pages
ALTER INDEX PK_BadClusterKey ON dbo.BadClusterKey REBUILD
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('dbo.BadClusterKey'), NULL, NULL, 'DETAILED')
-- 29 pages
GO

You can see how the size of the index is now smaller because we got rid of the fragmentation.
So far I haven’t show you the real deal, because with a new table is difficult but since we now have a number of rows and virtually no fragmentation, we can see the effect of inserting new rows.
Before doing so I want to be sure all my transaction rows will stay in the log, so time for a backup.
BACKUP DATABASE bad_cluster_key TO DISK = 'NUL' GO BACKUP LOG bad_cluster_key TO DISK = 'NUL' GO CHECKPOINT GO
Now we are ready to do another 10 (random) INSERT and see what has been going on there.
INSERT INTO dbo.BadClusterKey DEFAULT VALUES
GO 10
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('dbo.BadClusterKey'), NULL, NULL, 'DETAILED')
GO
-- 38

You can see how we have grown 9 pages, almost 1 page per row we have inserted… wow! that’s huge!
First and most noticeable consequence is fragmentation, but that’s not deep enough. I was performing a full plus transaction log backups to have less activity in our transaction log so I can find the 10 row I’ve just inserted easily.
SELECT [Begin Time] , [Transaction ID] , [Transaction Name] , [AllocUnitName] , [Page ID] , [Slot ID] , [Parent Transaction ID] , SUSER_SNAME([Transaction SID]) AS [Login Name] , [New Split Page] , [Rows Deleted] , [Description] --, * FROM fn_dblog(NULL, NULL) GO
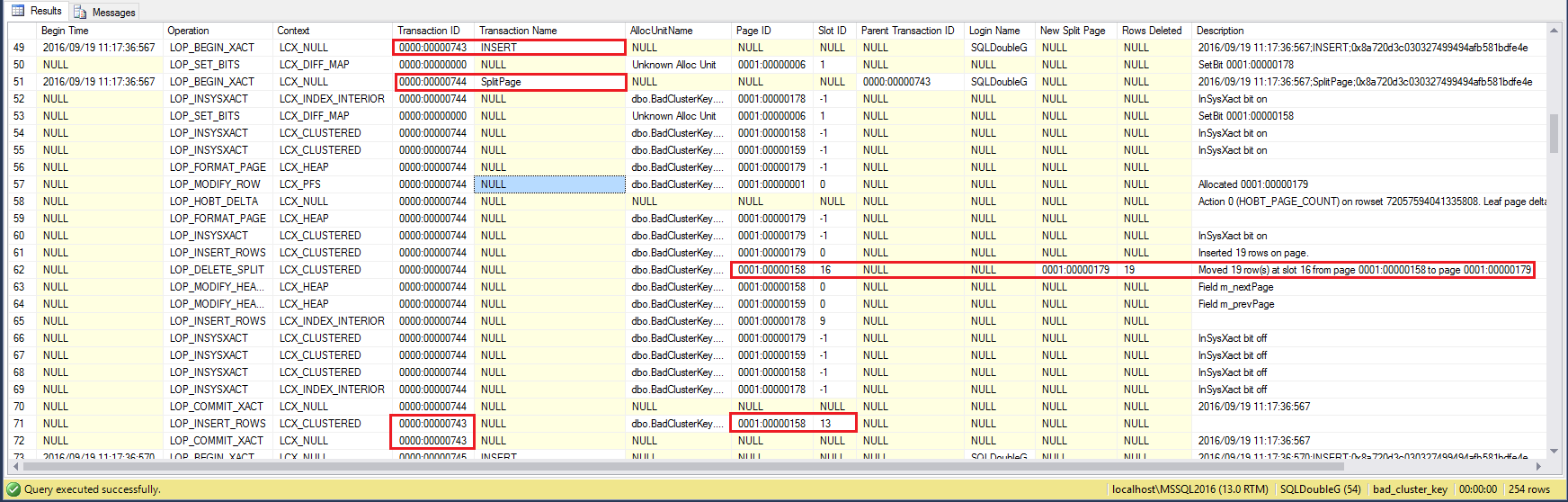
That’s still hell of a lot of information, so I’m going to focus in a single INSERT (transaction) and to show you what I’m interested in:
- – (Row 49, transaction ID ~0743) We have a row to be inserted which happens that must be placed in a specific page, because the clustered index enforces how the data is stored and that is sorted by the key.
- – (Row 51-70, transaction ID ~0744) The storage engine has detected there is not enough free space in that page to fit another row, so it has to make room by splitting the page.
There are many things to get done, hence the amount of records in the transaction log. - – (Row 62) Half(~ish) the rows are moved from one page to a new page, description can’t be clearer, Moved 19 row(s) at slot 16 from page 0001:00000158 to page 0001:00000179
- – (Row 71-72) Now that there is enough free space, transaction ~0743 can complete and the new row is finally inserted in its natural place, in this case page 0001:00000158, slot 13
All this trouble just to get one new row inserted. If this was happening on regular basis, imagine what a waste when almost each INSERT results in a page split and then your maintenance task have to go and remove the fragmentation by rebuilding the clustered index (which is not online unless Expensive Edition) and all the log to be sent to your HA/DR replicas…
The physical row
Hopefully so far everything makes sense, so let’s check those 2 pages to see how the data is stored, to see inside any specific page we use DBCC PAGE(). In a new Query window we run:
USE bad_cluster_key GO -- Moved 19 row(s) at slot 16 from page 0001:00000158 to page 0001:00000179 -- We need to convert from Hexadecimal to decimal SELECT CONVERT(INT, 0x0158), CONVERT(INT, 0x0179) -- 344 377 GO DBCC TRACEON(3604) GO SELECT DB_ID() -- 12 DBCC PAGE(12, 1, 344, 1) /* OFFSET TABLE: Row - Offset 16 (0x10) - 3441 (0xd71) 15 (0xf) - 3218 (0xc92) 14 (0xe) - 2995 (0xbb3) 13 (0xd) - 7901 (0x1edd) <----------- This is our row 12 (0xc) - 2772 (0xad4) 11 (0xb) - 2549 (0x9f5) 10 (0xa) - 2326 (0x916) 9 (0x9) - 2103 (0x837) 8 (0x8) - 1880 (0x758) 7 (0x7) - 1657 (0x679) 6 (0x6) - 1434 (0x59a) 5 (0x5) - 1211 (0x4bb) 4 (0x4) - 988 (0x3dc) 3 (0x3) - 765 (0x2fd) 2 (0x2) - 542 (0x21e) 1 (0x1) - 319 (0x13f) 0 (0x0) - 96 (0x60) */
DBCC PAGE(12, 1, 344, 3) /* Slot 13 Column 1 Offset 0x4 Length 16 Length (physical) 16 ID = e75e82eb-74d6-4502-bdc1-507fe87323fb Slot 13 Column 2 Offset 0x14 Length 100 Length (physical) 100 Col1 = AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA Slot 13 Column 3 Offset 0x78 Length 100 Length (physical) 100 Col2 = BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB Slot 13 Offset 0x0 Length 0 Length (physical) 0 */
We’ve seen the message ‘Moved 19 row(s) at slot 16 from page 0001:00000158 to page 0001:00000179‘.
So, after moving 19 rows, 16 were left in this page (Slots 0-15) and then the row was inserted (slot 13) hence we have now 17 rows (slots 0-16).
See how row (slot) 13 is at the end of the page (offset 7901), not immediately between 12 and 14, but that’s not important as far as it is sorted correctly in the slot array, where obviously it is.
If we check the new page generated by the split page operation we can see how for sure we have the 19 rows moved from page 344.
DBCC PAGE(12, 1, 377, 1)
/*
OFFSET TABLE:
Row - Offset
19 (0x13) - 4110 (0x100e)
18 (0x12) - 3887 (0xf2f)
17 (0x11) - 3664 (0xe50)
16 (0x10) - 3441 (0xd71)
15 (0xf) - 3218 (0xc92)
14 (0xe) - 2995 (0xbb3)
13 (0xd) - 2772 (0xad4)
12 (0xc) - 2549 (0x9f5)
11 (0xb) - 2326 (0x916)
10 (0xa) - 2103 (0x837)
9 (0x9) - 1880 (0x758)
8 (0x8) - 1657 (0x679)
7 (0x7) - 1434 (0x59a)
6 (0x6) - 1211 (0x4bb)
5 (0x5) - 4333 (0x10ed)
4 (0x4) - 988 (0x3dc)
3 (0x3) - 765 (0x2fd)
2 (0x2) - 542 (0x21e)
1 (0x1) - 319 (0x13f)
0 (0x0) - 96 (0x60)
*/
See how there are 19… errrrr 20? OMG! hahaha… don’t loose your faith just yet! there is one extra row because since our 10 INSERT are random, probably another row happened to be inserted on this very page, see how slot 5 is also at the end of the page, so I can be certain that insert can be found later in the transaction log.

There you go! Another INSERT in the same page (x0179 → 377) slot 5. Boom!
Concepts/Take away’s
Writing this demo has been pretty awesome for me and I have to say I needed to do this process at work to find the latest inserted rows in a table where the clustered key was not an IDENTITY value, so all these geekin’ around has some real value, internals are so cool!
And just to wrap up some of the concepts I have used or referenced in this post.
– The Clustered Index debate by Kimberly Tripp
– Index Fragmentation by Paul Randal
– Backup to NUL by Gail Shaw
– fn_dblog() by Paul Randal
– DBCC PAGE by Paul Randal
Thanks for reading!
Raul – Another great post.
I have run into the same things many times. In a perfect world primary keys would not allow UNIQUEIDENTIFIERs, but in reality it turns out that some people love to use them without a good understanding for the performance implications.
I have been able to mitigate the performance impact, the amount of fragmentation and the page splits by convincing developers to use NEWSEQUENTIALID() rather than NEWID(), its not awesome, but it does help with the excessive fragmentation that you get from a primary key using a random value like you get from NEWID().
I am curious on your thoughts and how this demo would go with NEWSEQUENTIALID() instead of NEWID()? Have you tried it?
Just to clarify I don’t want to become and advocate for UNIQUEIDENTIFIERs, but I have seen less page splits and fragmentation by simply switching to NEWSEQUENTIALID. I would still prefer an INT IDENTITY, or BIGINT IDENTITY.
-Steve Stedman
Thanks Steve, nice to see you around.
For your question, yeah I absolutely agree with that. If UNIQUEIDENTIFIER is a ‘must’*, NEWSEQUENTIALID() is a much better choice as you’ll reduce page splits.
The problems related to a wide clustered key still exist, but at least you won’t get much fragmentation (I tried indeed).
Paraphrasing Kimberly Tripp, “the ideal clustering key is narrow and ever increasing.” Also note that NEWSEQUENTIALID does not guarantee to be ever increasing as after a windows reboot can start again from a lower range as per BOL.
As I see it, all this is more about the randomness than the data type, just imagine if your clustered index is on the National Insurance Number, that’d be pretty random too 🙂 or date of birth.
*(filestream eg. requires a unique ROWGUIDCOL, but it doesn’t say you need to cluster your table on it)