Sooner or later the more you know how SQL Server works will help you come up with more and more ideas to solve your daily problems, let me show you what one of my problems is and how I approach it Disclaimer: This is how I solved a particular problem after analyzing and understanding my data. Any other case would require in-depth analysis and the mileage may vary.
And here I am again, speaking about best practices… Am I? Not really, I just want to show to all of you that wouldn’t believe me otherwise, how all the pieces in this SQL Server puzzle connect perfectly and give you the best picture possible.
In previous posts I showed you the fatal consequences of taking the wrong choice when you choose the datatypes for your columns and also the wrong clustering key for your tables.
But all this I tell you can sound very remote from our day-to-day tasks, like I had to thoroughly prepare them to fail and show meaningful results. And that might not come across everybody, I’ll take that.
So, keep reading if this time you want to accompany me down to my real world, and see how I approached this task.
Background
At work I deal with multiple databases of any kind and shape, some of them are small in the hundreds of Megabytes, and some of them are in the range of multiple Terabytes from 2TB to 10TB.
Most of this data is not relational and pictures and XML documents bloat my server, converting maintenance windows in such a pain… de-fragmenting indexes, updating stats, running CHECKDB and backups would take days to run if I wanted to run it one after another.
So at work, I’d say space matters, and in order to optimize our storage requirements it’s very important to know about SQL Server internals, specially the Storage Engine, which happens to be one of my favorite topics of study. 🙂
In my quest to release some space I got to this database, just one table which is 165M of XML documents stored as NVARCHAR(MAX). Let’s see what BOL says about it:

So each character stored in my NVARCHAR(MAX) column will take 2 bytes instead of 1 byte if we use VARCHAR(MAX), and that is ok as far as you have a good use of them. But is this my case?
Selecting random XML documents I noticed that most of those documents did not contain special characters that require all those extra bytes, but what to do? Let’s explore the different possibilities
- Change to VARCHAR(MAX) → Not a real option, since there are documents that will loose content if converted
- SQL Server compression → Enterprise only feature, data compression works on 2 different levels, ROW and PAGE, being the latter built on top the first one.
- ROW compression, will make all our columns variable length and UNICODE will become ASCII when possible, removing the extra byte required to store each character. The caveat is that row compression only affect UNICODE when the length is not MAX and most of my documents will exceed this 4000 limit.
- PAGE compression works differently, doing prefix compression and dictionary compression so it works very well when we have a good number of rows, because in a simplified view, each value only records the differences to the previous. I wouldn’t go this way since we will barely store one doc or two per page.
- Native GZip compression, this would be awesome, but unfortunately I’m still in SQL 2014, so it’s not available for me yet.
- BE CREATIVE, that sounds like a challenge…
Redesigning my table
Coming up with a new table layout seems like the best choice for me at this point, although painful because moving TB’s is not quick. And we have the extra challenge of not having to modify the programability and the UI which connects to this database.
The new logical layout will consist in 3 different tables which will join together in a view that will replace the old table, so this way I would have just minimal changes on SP’s and functions.
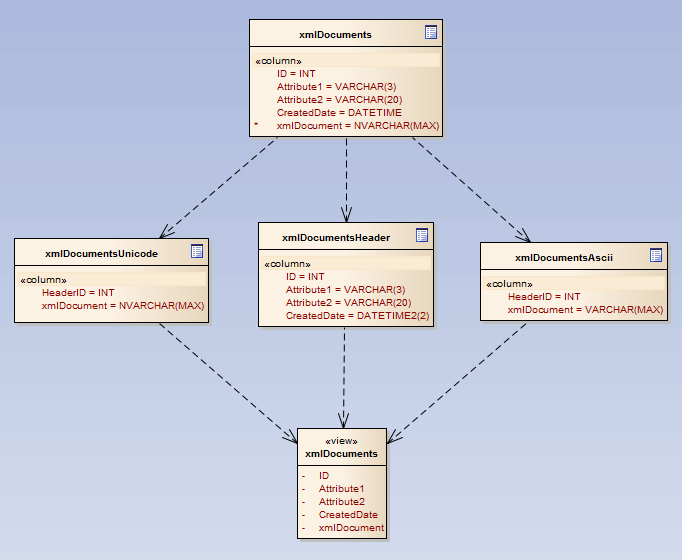
This technique is called vertical partitioning where we leave the most used columns on a master table and less used (or bigger in my case) in a different one, two in my design.
It gives better page density and therefore better accessibility to the columns more frequently used, but in my case, allows me to stored the XML documents on two different tables depending on the need of storing UNICODE or just ASCII.
This “simple” design change will give me the big bang for the buck since, at once and for good, all ASCII will automatically will be reduced to half its size, so the more ASCII vs UNICODE, the bigger gain.
In my case my ratio is in the range 70% ASCII vs 30% UNICODE, so reducing 70% to its half means a lot if 100% is over 2TB.
Is that all?
After all these years reading, writing, experimenting with SQL Server, going to SQL Skills Immersion Events, is this the far I can go? No way! 🙂
I told you all the knowledge you can gain about internals, sooner or later pays off. And I’m going to prove it!
The physical design
We have seen the logical design along with the correct data types for each specific case will be the big gain here, but the physical layout can give us another extra ~5%, let me show you how.
BLOBs stored in VARCHAR(MAX) and NVARCHAR(MAX) will stay in row as far as they fit in as single page, if not, they will go to LOB allocation units. The problem here it’s that the more rows I can fit in a single page the higher page density I will get, hence the less pages I will use to store the same data.
But how can I do that? Just going wild…
Clustered index by definition will sort the data by the clustered key, but does it make any sense in here?
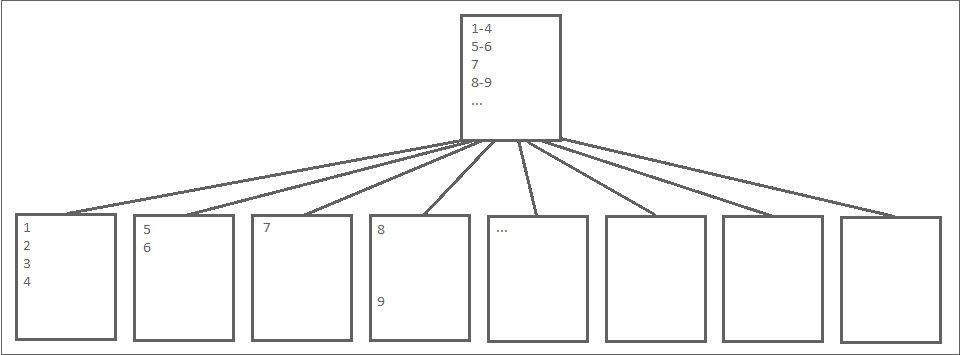
Enforcing a strict order is usually good, but for me, since this is just a “container” I don’t really care if they are sorted or not, I just want to get any single one of them quickly, I’m not going to scan the whole table.
And why this order matters? Because let’s say in the picture above document 4 does not fill up that page but the space is not big enough for document 5, hence doc 5 need to go to a different page. Is anyone ever going to use that remaining space? NO, because if sorted, nothing is between 4 and 5.
Creating them as HEAPs will make that if document 18 fits between 4 and 5, it’ll go there, giving me again better page density and consuming less space in disk. BOOM!!

Sometimes we need to understand that not following “best practices” blindly can be a good idea as far as we have a deep understanding of what we’re doing and why we are doing it. This is one of those cases where you can see that my previous posts about storage requirements and lookup performance make a lot of sense.
First Results
Now it’s the time to see if all this changes finally result in a good gain storage wise, so I’m going to provide the numbers of my test first and then explain them.

The original table has +165M rows and 2,1TB and my exercise will have the same number of rows but split in 3 tables, so numbers will be for real.
Simple maths will tell me:
- About 31% of my documents has UNICODE
- New layout has result in an improvement of about 30%
- For the new header table, the index size is half the size, since there are way less leaf pages, the index tree is considerably smaller
It’s ok, don’t get me wrong, but I can’t take this and be happy, there are still more than 900GB of UNICODE bothering me a lot.
Squeeze it till the last drop
It’s good how far we’ve got till now, but is there any juice left there? Sure there is…
As I explained before UNICODE can be compressed using ROW compression as far as it’s not MAX, so that gave me the idea… What if we keep it that way? For sure it will make things a bit more complicated to insert and update them, but it might be totally worth it.
And how to accomplish it? Just splitting those big documents in fragments that don’t exceed 4000 characters and take advantage of the ROW compression. Then when it’s time to retrieve a document we just have to concatenate the distinct fragments to serve one piece, cool, isn’t it?
The new layout will be quite very similar to the previous one, just modifying the Unicode table to take fragments.
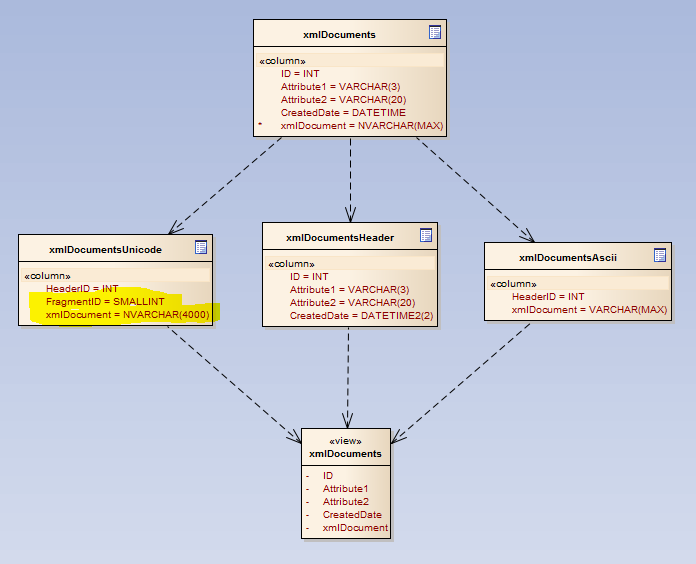
In order to split the documents in chunks, I didn’t want to reinvent the wheel, so I will use a modified version of Jeff Modens’s function 8k CSV splitter but just taking fixed chunks of 4k characters.
Again the mileage will vary for each case, but since xml contains a lot of tags which are ASCII, the gain can be worth the trouble and first numbers were promising,
The process is again a bit tedious, but the result will show if it’s a good deal to burn those extra cycles splitting the files to write those files to disk comparing to the amount of storage I can save.
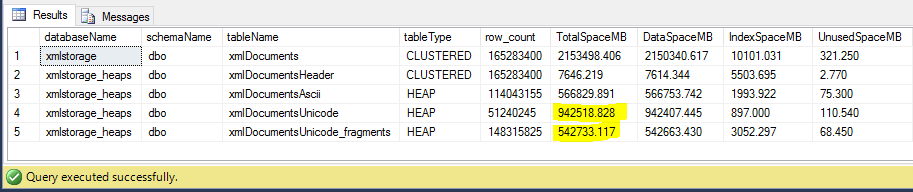
Wow! That’s nice! Using ROW compression I’ve been able to save another extra 400GB which makes the total savings up to 48%, that is almost half of the original size. I’ll take it!
Conclusion
This has been really exciting exercise (which hopefully will go production soon) with a lot of concepts involved, from logical design to physical design, storage internals and using enterprise features like compression trying to squeeze my data till the last byte.
All techniques involved here require in-depth knowledge before jumping to using them, because they are the kind of decisions that might affect your database performance.
SQL Server is no different from any other field, and you can get to the same place using different paths but each way will bring pros and cons, my pros are clear, up to nearly half of the storage requirements, the cons are I’ll burn much more CPU to get those docs into the database and also to retrieve them, but for my requirements that is ok, and maybe for yours it’s not, so be aware.
Hope you enjoyed as much as I did and thanks for reading!
Very interesting and informative. Really illustrates the need to think before converting your logical model to an equivalent physical model without stepping through the various ramifications of your choices.
Thanks for your comment! Glad you enjoyed it.
Cheers!
With 6K chars per XML on average ((2150340MB-7614MB-315MB)/165283400=13KB) and 31% UNICODE I’m wondering what’s inside…any chance PII data that have to be encrypted/masked sooner or later? Little detail.
Personally, I’m careful with symmetry in physical layouts (had lots of problems in the past) and would consider merging xmlDocumentsAscii and xmlDocumentsUnicode into xmlDocuments (separate columns for Unicode and Ascii) with 1:1 PK/FK to Header. True vertical partitioning not hybrid. FragmentID/splitter logic can be applied to xmlDocumentsAscii as well.
BE CREATIVE, that sounds like a challenge…OK:
1. VARBINARY(MAX) FILESTREAM on compressed volume (doesn’t use buffer pool, but your XMLs can be bit small)
2. VARBINARY(MAX) compressed on client side (+1 for network/CPU scalability)
3. Compress data on SQL with custom CLR – fine for SQL2014 (I know you know)
4. MAX(INT) is 2^31-1 which is not far away if you have gaps in IDs
5. Don’t use SQL Server at all. If its ‘document store’ only – then there are better dbs…
6. FragmentID SMALLINT seriously? – not TINYINT? (that’s to cheer you up!)
Have fun!
Haha, lots of questions here, I like it!
– The XML data itself contains open patents, so there is no need to encrypt that.
– 1 Table instead of 2 -> It’s more consistent, yes. But I’ll have to burn more CPU to chop it and concatenate it back, adding the compression bit can be too much, but it’s something I have considered myself.
– Filestream? not a real option, it just can’t cope with 170M rows, I spoke about this with P. Randal and confirmed it (he wrote the whitepaper back in 2008)
– Client side compression or CLR? Good one, but I have to do this without involving any side work for other teams and I’m not a c# expert..
– MAX(INT), not sure what you mean there
– Not using SQL Server? too late I’m afraid.. I wish, but not a real option at this point
– fragmentID SMALLINT? the biggest fragmentId so far it’s 10700, so yeah, no TINYINT will cope with that. MAX(LEN()) = 42802079
Cheers!
> [DS] MAX(INT) is 2^31-1 which is not far away if you have gaps in IDs
>> [GG] MAX(INT), not sure what you mean there
I meant INT range. Table is not small – xml generation ratio and ID design can cause problems.
Thanks
Thanks for the excellent post. Not sure if you need to change the datatype of “xmlDocument” in “xmlDocumentsUnicode” in final image where FragmentID is added.
Thanks for your comment! very true, that should be NVARCHAR(4000) good catch!
Cheers
*Post updated
I’d be curious about the performance related to reassembling the Unicode fragments.
I do like the idea of bursting the clustered index best practice idea. There are places where heaps can easily outperform as long as you work within some guidelines and do adequate testing.
Thanks for your comment!, there is some overhead putting all fragments together of course, but the accessing pattern is one document at a time which is accessed using the non clustered index on headerId and fragmentId (they still are the primary key although non clustered).
For bigger documents I’ve seen up to 10k fragments and the performance is obviously worse, see numbers below
— Fragments
SQL Server Execution Times:
CPU time = 1469 ms, elapsed time = 3988 ms.
–Single doc
SQL Server Execution Times:
CPU time = 281 ms, elapsed time = 2681 ms.
That is a big doc and waiting just a bit longer it’s ok for my requirements.
Cheers
This blog sharpens my skills.