Query plans are very useful to tune queries, but some operations are usually avoided or blamed for performance problems when not always are the culprit, let me show you one of those rear cases where the theory does not apply I understand that if you want to keep up with technology (or at least try), you must spend a great deal of your time reading about it, no matter if you use Books online, you buy books from the shop or what I enjoy the most, read blog posts and technical articles.
So I’m reading an article from Klaus Aschenbrenner (b|t) called The Performance Penalty of Bookmark Lookups in SQL Server which explains the performance degradation you might suffer from bookmark (or Key) lookups.
All good, he’s a reputed expert and knows what he’s talking about and I don’t pretend to say he’s wrong, cause he’s not, but let me show you the 0,000001% which makes SQL Server such an amazing system.
Background
I’m not going to get into many details about bookmark lookups as you can read Klaus’s article, which I recommend, but as always there is a ‘it depends’. And I’m going to show you something I found just last week and I kept the query plans to explain.
As I said, 99.999999% (polite guess) of the times, the query optimizer will choose a covering index since it’s just one place to read from, avoiding expensive nested loop operators and the fearsome lookups. And that makes a lot of sense.
But in some conditions and where there is another index that can be used, the optimizer can choose (wisely done) to use that index and then perform the lookups. Let me show you the anonymized queries and their query plans.
SELECT DISTINCT
Object1.Column1 ,
Object1.Column2 ,
Object1.Column3 AS Column4 ,
Object1.Column5 AS Column6 ,
Object1.Column7 AS Column8
FROM Schema1.Object2 AS Object1
INNER JOIN Schema1.Object3 AS Object3
ON Object1.Column1 = Object3.Column1
INNER JOIN Schema1.Object4 AS Object5
ON Object3.Column10 = Object5.Column11
WHERE Object1.Column12 = 'Value'
AND Object1.Column3 BETWEEN 'Date' AND 'Date'
AND ( Object5.Column13 LIKE '%String%' );
SELECT DISTINCT
Object1.Column1 ,
Object1.Column2 ,
Object1.Column3 AS Column4 ,
Object1.Column5 AS Column6 ,
Object1.Column7 AS Column8
FROM Schema1.Object2 AS Object1 WITH ( INDEX = Index5 )
INNER JOIN Schema1.Object3 AS Object3
ON Object1.Column1 = Object3.Column1
INNER JOIN Schema1.Object4 AS Object5
ON Object3.Column10 = Object5.Column11
WHERE Object1.Column12 = 'Value'
AND Object1.Column3 BETWEEN 'Date' AND 'Date'
AND ( Object5.Column13 LIKE '%String%' );
The first query doesn’t use the covering index I have created, so I decided to force it in the second query, the query plans are as follows
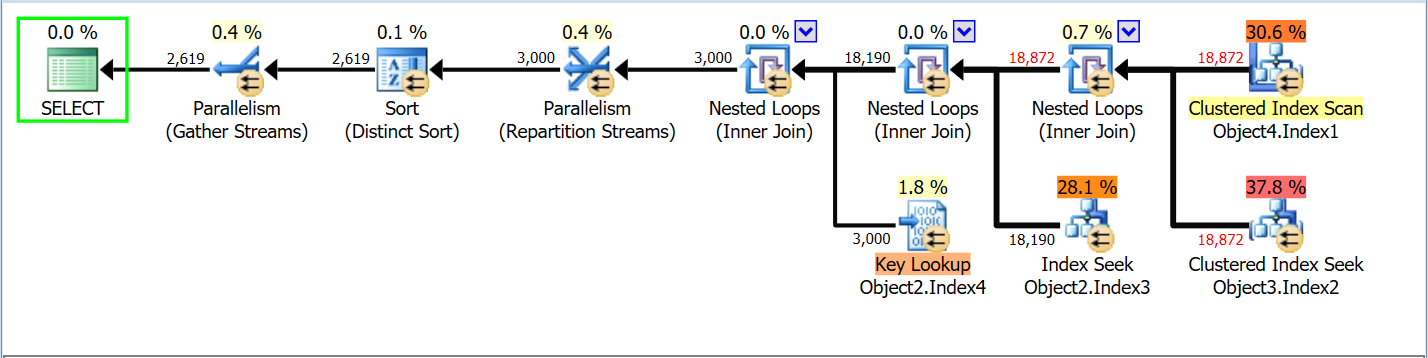
You can see that there are lookups, and I got really intrigued by this, did I missed a column to cover and this is why? So I decided to use a query hint to force the covering index. And this was the query plan
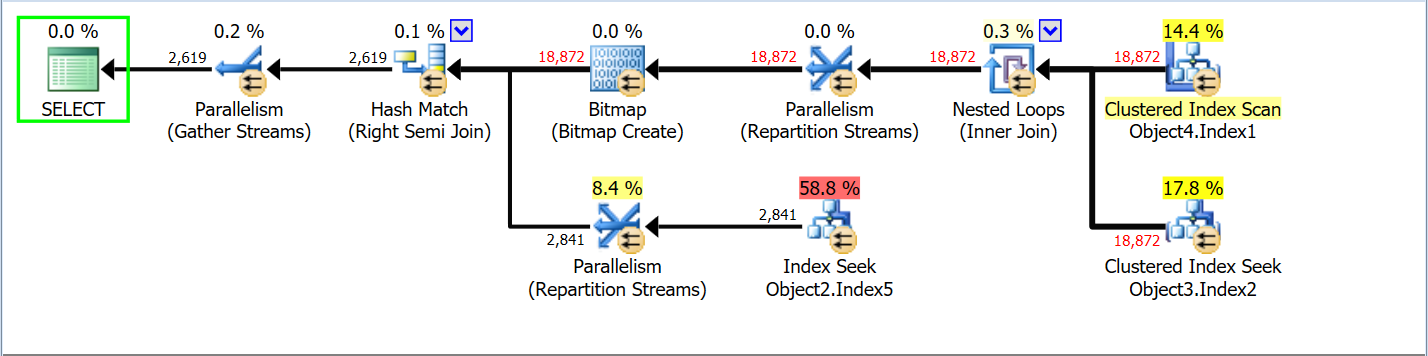
See how Object2.Index3 Seek + Object2.Index4 Lookup have become Object2.Index5 Seek. And in theory, that should be cheaper for SQL Server, so what is it thinking about? has it got crazy or something?
Not really.
Keep digging
Query plans are good for performance tuning but these are not the only tools we need to look at. Another great tool is STATISTICS IO and STATISTICS TIME being the latter a bit more ~ish in some aspects but in general both is what I use all the time to tune SQL.
The output for these two queries is
/* (2619 row(s) affected) Table 'Object2'. Scan count 0, logical reads 150702, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Object3'. Scan count 0, logical reads 76737, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Object4'. Scan count 9, logical reads 64938, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) SQL Server Execution Times: CPU time = 19716 ms, elapsed time = 2632 ms. (2619 row(s) affected) Table 'Object3'. Scan count 0, logical reads 76735, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Object4'. Scan count 9, logical reads 64938, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Object2'. Scan count 9, logical reads 293220, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) SQL Server Execution Times: CPU time = 24297 ms, elapsed time = 3071 ms. */
If we use StatisticsParser we get a much prettier picture
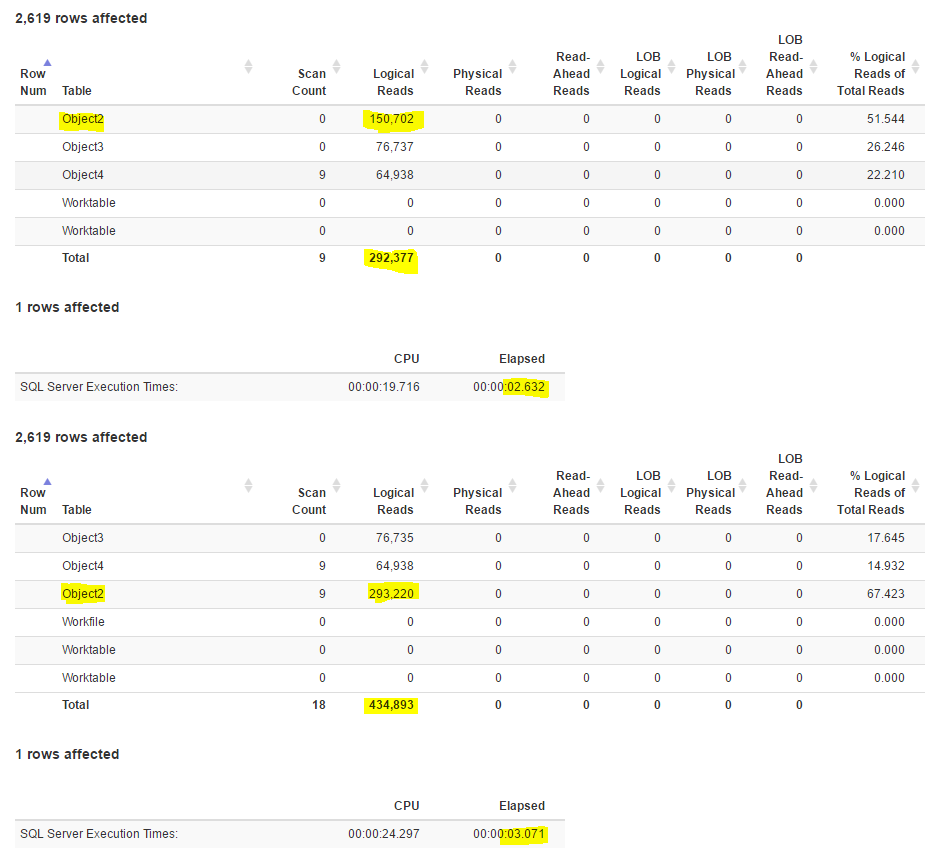
In the first query (the optimizer’s choice) the biggest table have nearly half the reads, including both indexes the one to seek and the lookup.
Forcing SQL to use the covering index in this case does not help, as it needs almost double the effort to satisfy the same query.
The big Gotcha
This is a very special case where the covering index has three keys and then a couple of included columns, one of which is NVARCHAR(MAX) column, so the covering index is pretty big and we only seek in the leftmost column, which is also possible using another much smaller index on that single column.
In both cases, the operator is able to push the query predicate(s) to the seek and thanks to that, the number of rows coming out the operator is not that big. But the number of rows which match the leftmost key and therefore have to be read is quite big.
Remember that even though you see ‘Seek’ what it is in reality a partial scan and depending on how big the portion to scan is and the number of rows we can fit in a page, the optimizer would use the narrower index as it might overcome the penalty of having to do lookups for the returning rows.
So I took the query and split it in a way to match the logical operator, having one query common to the two different query plans and then two variations, with a single lookup to the covering index and another with two the seek plus the lookup.
And looking at the output of STATISTICS IO is quite revealing:
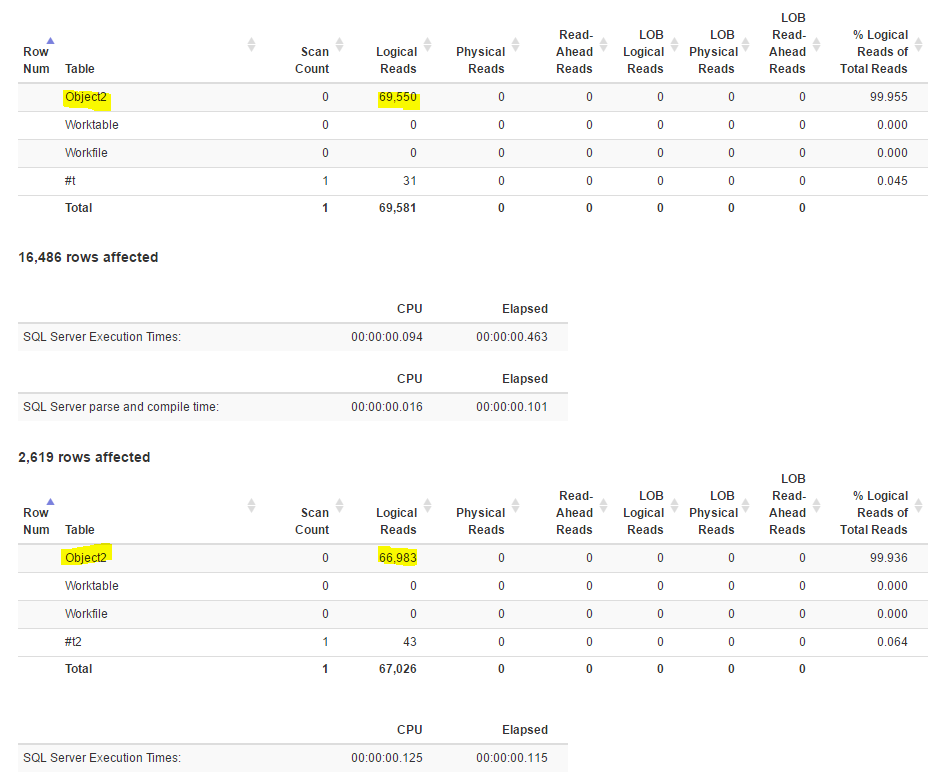
Both queries cause less reads in total, which means the two operators (seek + lookup) are, in this case, less expensive in IO’s than one seek (partial scan) on the wider covering index.
We can see them both to compare side by side.
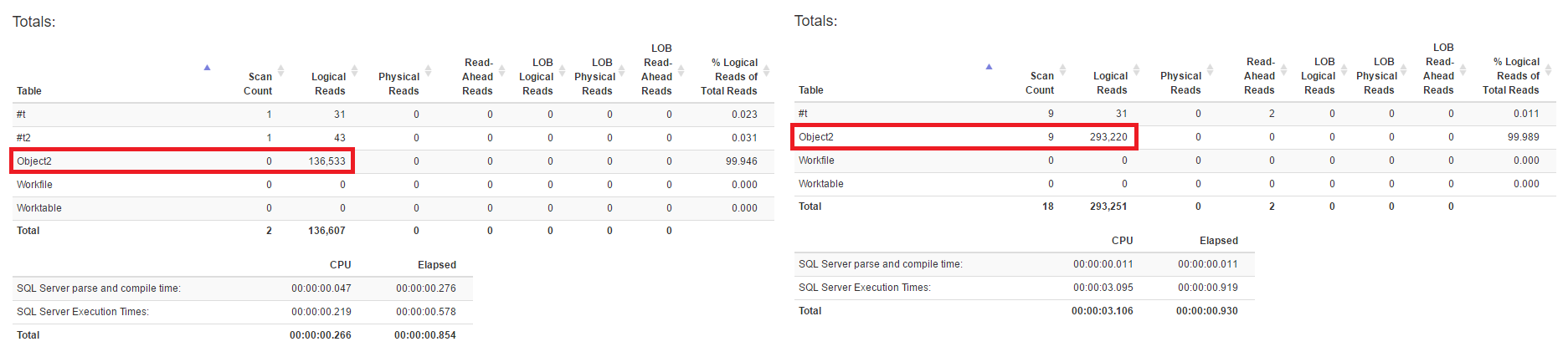
The left side tries to replicate the two lookups by using two staging temporary tables and the right one will use the covering index.
So due to the size of the covering index and the cardinality of the leftmost column, the optimizer thinks that using the a narrower index and then fetch the remaining columns for the rows would be cheaper than looking at the covering index, which results is more IO’s, about double reads.
Conclusion
This is a demonstration of how difficult and challenging to tune and optimize queries for performance is and the many factors that can be involved.
The facts explained do not contradict the general rule, but if there are more factors involved this can be ignored. Also comes again to prove that almost never there is a one-solution-fits-all cases when speaking about SQL Server, although this is a pretty rear case.
Obviously best practices and guidelines need to exist because they will cover the vast majority of cases but once we have followed them, we still can find things that surprise us.
I tried to replicate with different set of values and the covering index was the most common preferred choice, which makes the index worth even if there are some exceptions.
Thanks for reading and any question, use the comments below!