Here I am, trying to get back my habit and write about something useful I was working on the other day.
If you ask me which SQL Server feature I love the most these days I’d say, without hesitation, that is the Query Store.
Query Store has been around now for a number of years already, but I’m surprised that still lots of people haven’t used it to troubleshoot performance issues, to asses the general health of their systems or to capture a baseline for future reference.
Recently I was looking at some data collected by the Query Store and I found something interesting I want to share.

Background
A good database maintenance is mandatory if you want to have peace of mind, backups, integrity checks, statistics update and index maintenance.
Each of these steps will help you in a different way and should be altogether the foundation of a healthy environment for any DBA, but sometimes we might be overzealous and there may be some negative impact as side effect in our servers.
The simple reason is just because the available resources are finite and we might we wasting them by doing something that is a bit pointless.
Statistics
One if the most important (if not the most) when it comes to help SQL Server performance, it is Stats Updates because that is the key information the Query Optimizer will use to produce the best good enough plans for our data layout.
The problem comes when some of these stats are really useless, let me explain.
When AUTO_CREATE_STATISTICS is ON (best practice, do not turn it off), the Query Optimizer creates statistics on individual columns in the query predicate, as necessary, to improve cardinality estimates for the query plan.
That means that sometimes, stats might be created on columns that are not a very good fit due to the histogram nature or the way we access specific columns.
Scenario
For this demo I will use a copy of the StackOverflow database I restored in my localhost.
If we look at the stats created on the table [dbo].[Posts] we can see there is a number of them. This query will show them along with their data types, which is important.
USE StackOverflow
SELECT OBJECT_SCHEMA_NAME(c.object_id) + '.' + OBJECT_NAME(c.object_id) AS [object_name]
, s.name
, c.name
, t.name
, c.max_length
--, *
FROM sys.columns AS c
INNER JOIN sys.types AS t
ON t.user_type_id = c.user_type_id
LEFT JOIN sys.stats_columns AS sc
ON sc.object_id = c.object_id
AND sc.column_id = c.column_id
LEFT JOIN sys.stats AS s
ON sc.object_id = s.object_id
AND sc.stats_id = s.stats_id
WHERE c.object_id = OBJECT_ID('dbo.Posts')
ORDER BY c.column_id
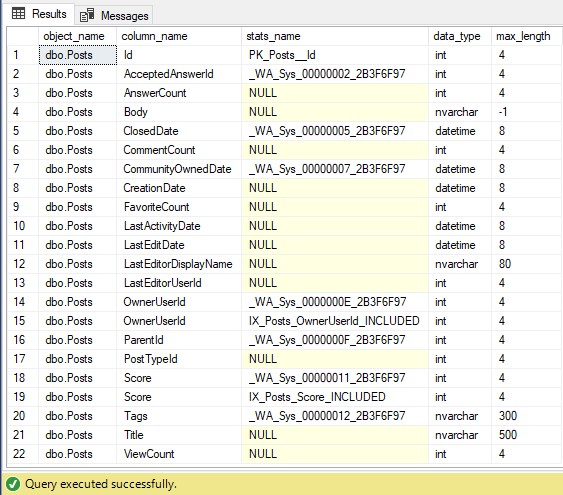
The column [Body] is defined as nvarchar(max) and currently there are no [column] statistics created on it.
Now, let’s say someone decides to run this query:
SELECT TOP(10) * FROM dbo.Posts WHERE Body LIKE '%sql server%'
If we have another look, we can see now there is a new stats on the column [Body], and by looking at the name, we can deduce it’s auto created.
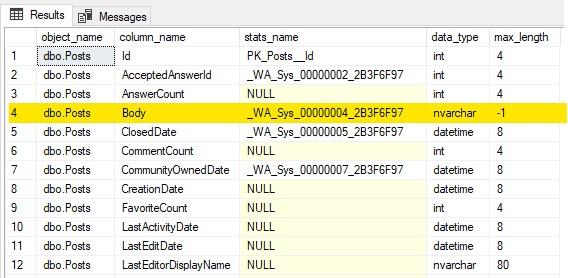
As mentioned earlier, stats play a key role during the execution plan generation, and inaccurate stats lead to all sort of performance issues.
The problem here is how stats (or the histogram in this case) is stored and the information SQL Server can extract to help to generate the most optimal plan.
Let’s have a look at the histogram for this stats.
SELECT *
FROM sys.dm_db_stats_histogram (OBJECT_ID('dbo.Posts'),11)
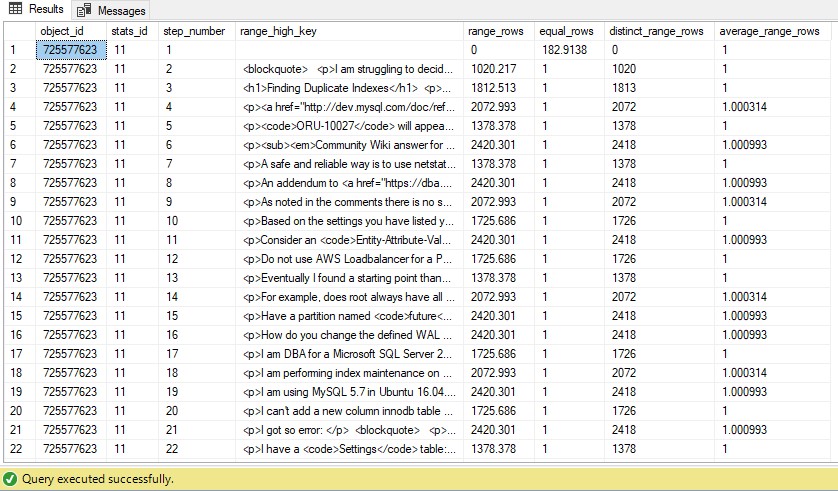
The values stored in the column [range_high_key] are actual values from the table’s column [Body] and since it’s great when we speak about integers, dates or short strings where we do equality, it’s not that great when we speak about others, like long strings or blobs for instance.
The Problem
For now, everything described might not be such a horrible thing, it’s clear that SQL Server will not take full advantage of the stats on the column [Body] if the queries we are running use wildcards (specially leading), but why so much fuss? Well, now it’s when things start making sense (or not).
Running stats maintenance on this kind of columns every night can become really expensive and this is what I’ve found more than once when using the Query Store to look for queries that have a high number of reads.

In the picture you can see how one single UPDATE STATS was incurring in ~60GB almost every night, which can be expensive.
The SQLG Hack
Even if you have used Ola Hallengren’s solution for a while, you might not be aware of every possible configuration because the default usually works just fine.
But here I am to tell you a little secret, there is a parameter called @Indexes to control which indexes you want to include or exclude from being maintained in the stored procedure [dbo].[IndexOptimize].

But although there is no equivalent for statistics and the documentation does not state it, you can also use it to exclude statistics, so we can programmatically look for those stats on the columns you think it doesn’t makes sense to update stats, because of the little return comparing the cost of doing it.
Once that is said, we can be creative and choose for instance those stats whose data types might not make be a good fit, like XML, [n]varchar(max), old style blobs (text, ntext, image), or [var]binary.
This is how I do it.
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_NULLS ON
GO
--=============================================
-- Copyright (C) 2021 Raul Gonzalez @SQLDoubleG.
-- All rights reserved.
--
-- You may alter this code for your own *non-commercial* purposes. You may
-- republish altered code as long as you give due credit.
--
-- THIS CODE AND INFORMATION ARE PROVIDED "AS IS" WITHOUT WARRANTY OF
-- ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED
-- TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A
-- PARTICULAR PURPOSE.
--
-- =============================================
-- Author: Raul Gonzalez, @SQLDoubleG (RAG)
-- Create date: 01/06/2021
-- Description: This script run IndexOptimize to Update Stats
USE master;
DECLARE @indexes nvarchar(MAX);
DECLARE @dbname sysname;
DECLARE @sql nvarchar(MAX);
DECLARE dbs CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR
SELECT name
FROM sys.databases
WHERE database_id > 4
AND name = 'StackOverflow';
DROP TABLE IF EXISTS #t;
CREATE TABLE #t (stats_name nvarchar(500) NOT NULL);
SET @sql = 'USE [?]
SELECT DB_NAME() + ''.'' + QUOTENAME (OBJECT_SCHEMA_NAME (s.object_id)) + ''.'' + QUOTENAME (OBJECT_NAME (s.object_id)) + ''.'' + QUOTENAME (s.name)
-- , c.name
-- , t.name
-- , c.max_length
FROM sys.stats AS s
INNER JOIN sys.stats_columns AS sc
ON sc.object_id = s.object_id
AND sc.stats_id = s.stats_id
INNER JOIN sys.columns AS c
ON c.object_id = s.object_id
AND c.column_id = sc.column_id
INNER JOIN sys.types AS t
ON t.user_type_id = c.user_type_id
WHERE OBJECTPROPERTY (s.object_id, ''IsMSShipped'') = 0
AND
(
t.name IN ( N''image'', N''text'', N''sql_variant'', N''ntext'', N''xml'', N''hierarchyid'', N''geometry'',
N''geography'', N''varbinary'', N''binary''
)
OR c.max_length = -1
)';
OPEN dbs;
FETCH NEXT FROM dbs INTO @dbname;
WHILE @@FETCH_STATUS = 0 BEGIN
SET @sql = REPLACE(@sql, '?', @dbname);
INSERT INTO #t (stats_name)
EXECUTE sys.sp_executesql @stmt = @sql;
FETCH NEXT FROM dbs INTO @dbname;
END;
CLOSE dbs;
DEALLOCATE dbs;
SET @indexes =
(
SELECT ',-' + stats_name
FROM #t
ORDER BY stats_name
FOR XML PATH ('')
);
SET @indexes = N'ALL_INDEXES' + @indexes;
-- SELECT @indexes
-- UPDATE Stats ONLY
EXECUTE dbo.IndexOptimize
@Databases = 'StackOverflow',
@Indexes = @indexes,
@FragmentationLow = NULL,
@FragmentationMedium = NULL,
@FragmentationHigh = NULL,
@UpdateStatistics = 'ALL',
@OnlyModifiedStatistics = 'N',
@LogToTable = 'Y',
@Execute = 'N';
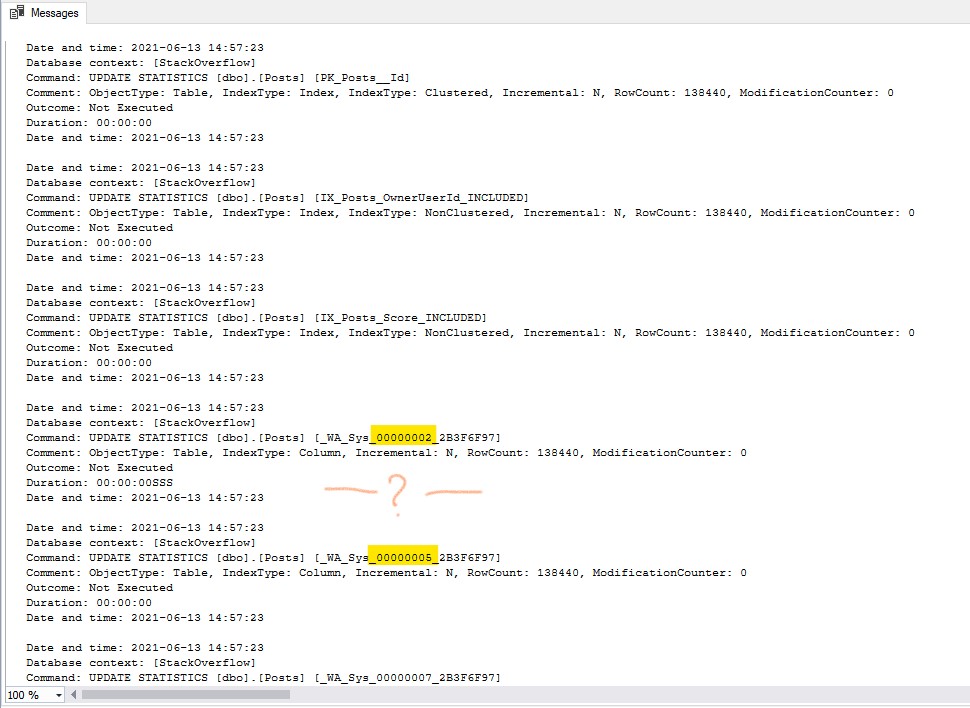
If we execute the above and look at the output, there are a couple of interesting things.
First, this message gives me the wrong impression that the syntax is not correct or the parameter will not work on stats (as I told you already)
The following indexes in the @Indexes parameter do not exist: [StackOverflow][dbo].[Posts].[_WA_Sys_00000004_2B3F6F97].
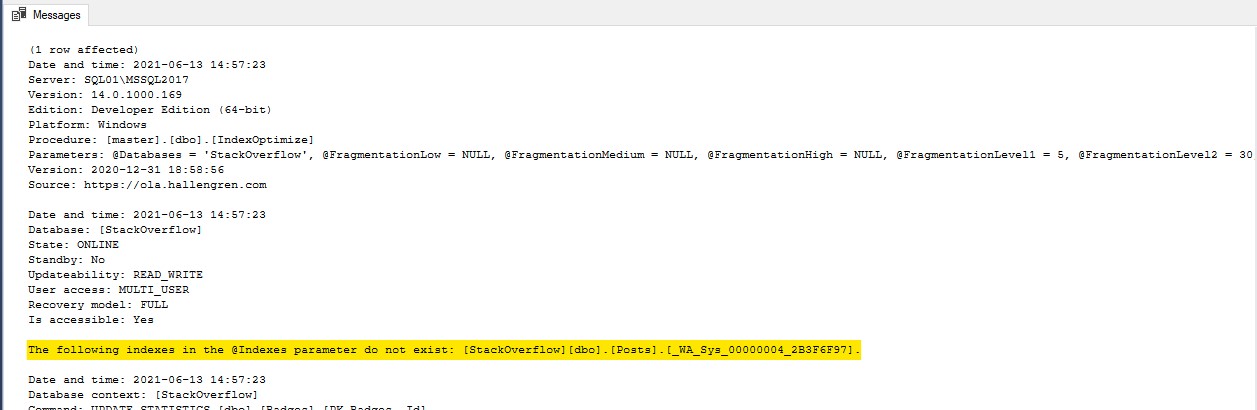
Second and most important is that it actually worked absolutely fine! If we scroll down to the table [dbo].[Posts], we can see the update stats commands for all stats, but not for the one on the column [Body] (called _WA_Sys_00000004_2B3F6F97), so our intention, which is to exclude it, was achieved.
The script is ready to go through all databases with a simple change, but I let you play with it and change it if you like.
Conclusion
I believe Ola’s solution is a pretty good tool and saves the bacon of lots of us which otherwise we will be re-inventing the wheel over and over.
Finding these little gems and with a bit of scripting, it becomes even more flexible, which is even better.
I hope you enjoyed the reading and please let me know if you found it useful in the comments.
Cheers!