This story might sound familiar for most of the DBA’s out in the wild. Our job to keep databases up and running, and sometimes, make them to go faster (I’m not going into what fast mean, just in case). Some other times, we have developers, that want their code to run faster, they seem to be impatient, not sure why 🙂 This story might sound familiar for most of the DBA’s out in the wild. Our job to keep databases up and running, and sometimes, make them to go faster (I’m not going into what fast mean, just in case). Some other times, we have developers, that want their code to run faster, they seem to be impatient, not sure why 🙂
And every so often we have to create indexes to make that happen, but is that the end of the journey? Are you sure having the index is enough? Is it going to be useful? Let’s see, here is your index, now what?
Background
The benefits of having an index are well known, you can get the same results by reading a smaller amount of data so the improvement in performance can be from several minutes to seconds or even less.
That sounds awesome and it certainly is and there are people out there making a living of it, so it’s a huge deal for sure.
But it’s not always like that, and things can go wrong very easily and make all these shiny indexes just a pile of useless burden.
Let me show you some examples, where we can see our indexes in use, but also how they can be ignored by the query processor and become totally useless. I’m going to use the Microsoft sample database [WideWorldImporters] so you can follow along if you want.
Desired behaviour
If we check the table [Sales].[InvoiceLines] we can observe there is a non clustered index on [PackageTypeID] so we expect that queries using this column to filter the results, will benefit from it. Just like this
USE [WideWorldImporters] SELECT COUNT(*) FROM [Sales].[InvoiceLines] WHERE [PackageTypeID] = 9
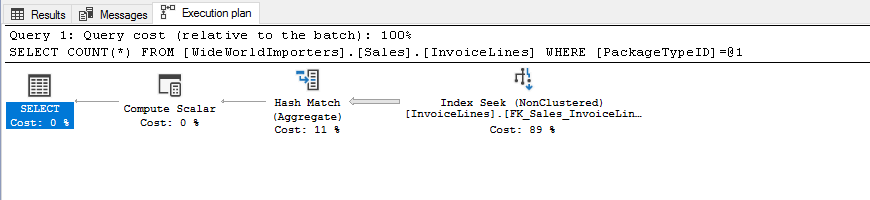
Another example we can see here.
USE [WideWorldImporters] SELECT * FROM [Sales].[InvoiceLines] WHERE [PackageTypeID] = 1
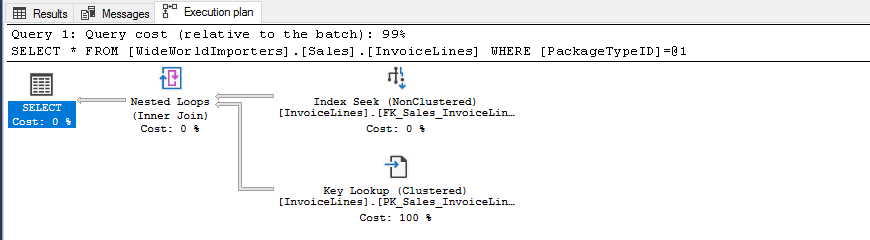
This second example is not as good as the first one, since we need to also perform Key Lookups to satisfy the query because we are requesting more columns than exist in the index.
Index Seek inhibitors
But not everything is rainbows and unicorns, there are days that indexes are useless, not their fault, usually ours, but at the end it doesn’t matter, our indexes are useless.
Statistics
We’ve seen the first query being the perfect example of what we are looking for, reading only from our index and only the rows we are interested in.
The second example started to get off the path and have to include another operation to get the rest of the columns that are not included in our non clustered index.
Following this second example we can find our first inhibitor, which I include although this is “benign”
The query processor uses statistics to determine the best query plan for each query and sometimes it’s more efficient to perform a whole clustered index scan than seek plus key lookups
USE [WideWorldImporters] SELECT * FROM [Sales].[InvoiceLines] WHERE [PackageTypeID] = 9
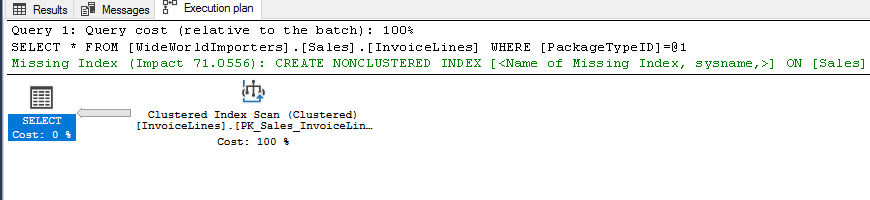
Didn’t I say statistics?, let’s see them
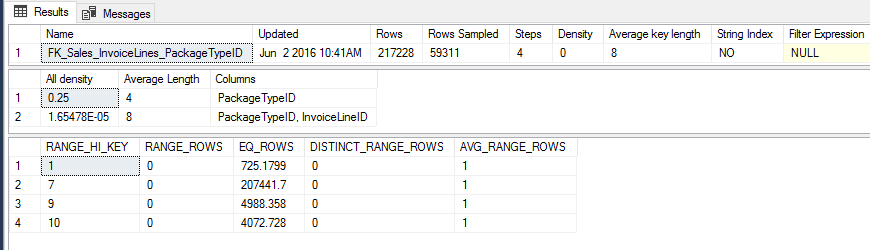
Observe how when we used the value 1 the optimizer believes Seek+Lookup is the most efficient considering there are only ~725 rows, but for value 9 there are ~4988 rows, too many lookups, hence the plan is just to scan the whole table and pick those rows that match the filter.
Somewhere between the number of rows for value 1 and 9 there is a spot called the “tipping point” one row above that threshold and the optimizer will change the plan from seek to scan. This is not necessarily something bad. The optimizer knows better most times.
Variables
Another problem we can have when optimizer looks at the index statistics is if we are not providing a value but a variable. Now the optimizer has to guess how many rows will be returned for this unknown value the query will run.
Let’s see for our value 1 when it’s in a variable.
USE [WideWorldImporters] DECLARE @PackageTypeID INT = 1 SELECT * FROM [Sales].[InvoiceLines] WHERE [PackageTypeID] = @PackageTypeID -- Estimated rows = 57066 -- Query plan Clustered Index Scan GO
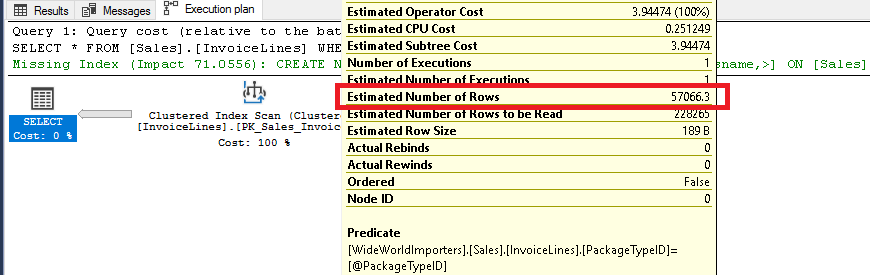
The optimizer calculates how many rows per value in average to guess how many rows will be returned and this number happens to be over the tipping point so the plan is to perform a clustered index scan.
Considering the cardinality of this column (index) where the number of rows for most values and the average are over the tipping point, it’d be more sensible to always perform a table scan.
This makes our index totally useless in most cases…
More problems related to statistics, parameter sniffing
Running the batches above probably is not the most common thing we do. We usually write stored procedures for re-usability.
The problem is that if the first time we run the procedure we provide the value 1, the plan would be “seek + lookup” and it will be like that regardless the value in subsequent executions, while the plan is in the plan cache.
If the first value is 9, then the clustered index scan would be the choice.
I’m not going to get more into this as the topic is wide enough to have a whole post or session, just Bing/Google it and you’ll see possible solutions for this problem.
Bad T-SQL
Because be honest, sometimes we write code that stinks.
Let’s imagine we have another index that on both cases, for specific values or for variables it always return index seek + key lookup and that also happens to be the most efficient way… How does that sound? good innit?
And now imagine we just write code and we screw it 🙁
DBCC SHOW_STATISTICS ('[Sales].[InvoiceLines]', [FK_Sales_InvoiceLines_StockItemID])
/*
Avg -> Rows * All density = 951
RANGE_HI_KEY EQ_ROWS
1 1097.179
2 991.8209
3 999.087
4 1060.849
... ...
*/
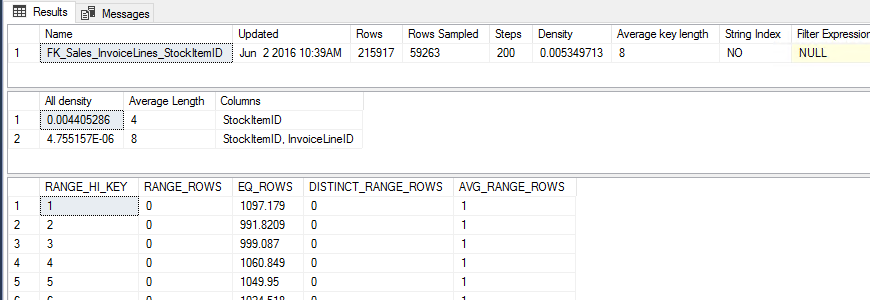
The data is evenly distributed, so each value and the average (using a variable) produces the same query plan, non clustered index + key lookup.
USE [WideWorldImporters] SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = 1 -- Estimated rows = 1159 -- Query plan Index Seek + Key Lookup GO DECLARE @StockItemID INT = 1 SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = @StockItemID -- Estimated rows = 1005 -- Query plan Index Seek + Key Lookup GO
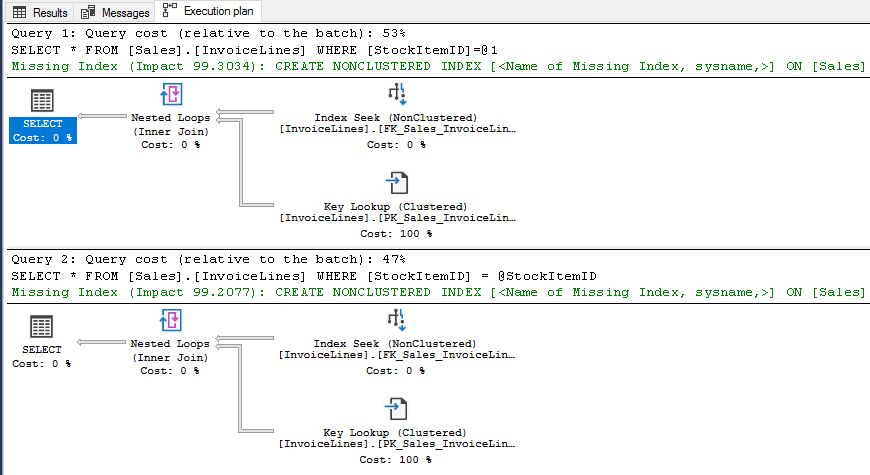
This example is perfect, so what can go wrong?, easy, how many times we have to write code like this?
USE [WideWorldImporters] DECLARE @StockItemID INT = 1 SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = @StockItemID OR @StockItemID IS NULL
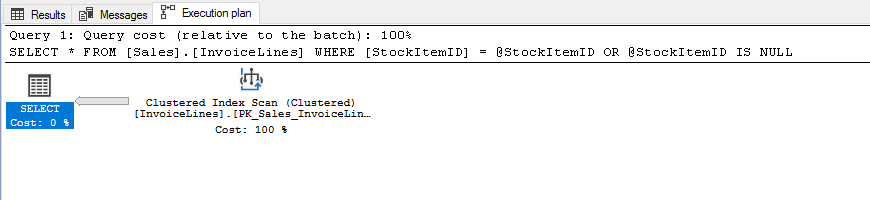
BOOOM!!! there you go, here is your useless index.
So, what can we do now?
There’s no pretty solution I’m afraid. And as always… “it depends”
Obviously we have to consider many factors, because it is not so common to have a process as simple as just one query. The complexity of it as much as the frequency we execute it might determine the final solution.
One of the possibilities would be to write two queries and execute one or another depending on the value of the parameter.
DECLARE @StockItemID INT = 1 IF @StockItemID IS NULL BEGIN SELECT * FROM [Sales].[InvoiceLines] END ELSE BEGIN SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = @StockItemID END
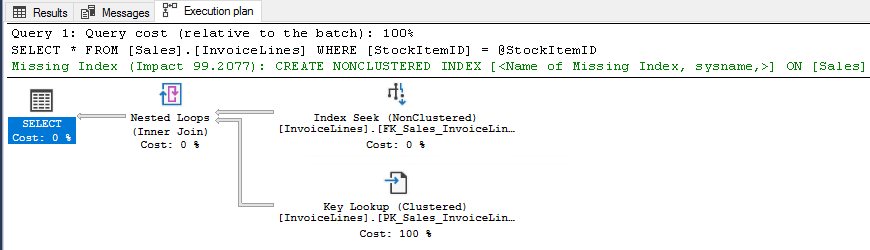
and if we pass NULL, the query plan would be
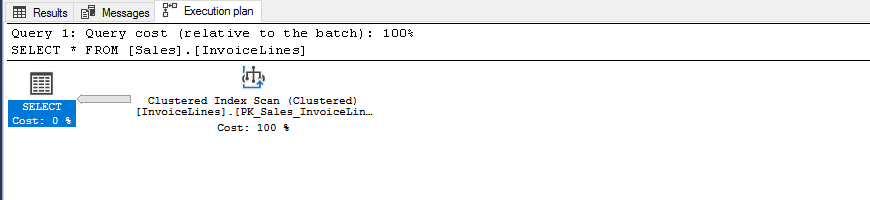
The other option I propose is to use OPTION(RECOMPILE), but we need to be cautious with this solution because of the possible overall performance hit of recompiling, as this is not free in CPU terms, so keep that in mind.
It’d be like this
USE [WideWorldImporters] DECLARE @StockItemID INT = 1 SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = @StockItemID OR @StockItemID IS NULL OPTION(RECOMPILE)
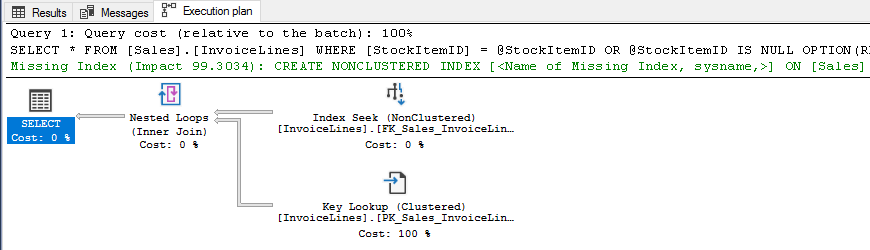
Conclusion
You can see how easy things can turn around and make our brand new and shiny index to be absolutely useless. This has been just a simple example but I hope enough to make you aware of how difficult is to tune queries to improve the performance.
Thanks for reading and please tell me in the comments what you think about this or other cases you might have suffered.