Es posible que esta historia suene familiar para la mayoría de DBA’s que están ya experimentados. Nuestro trabajo consiste en mantener las bases de datos funcionando y, de vez en cuando, hacer que sean más rápidas (no voy a entrar en que significa rápido, por si acaso). En otras ocasiones, tenemos desarrolladores que quieren que su código se ejecute más rápido, no se a que tanta prisa la verdad Es posible que esta historia suene familiar para la mayoría de DBA’s que están ya experimentados. Nuestro trabajo consiste en mantener las bases de datos funcionando y, de vez en cuando, hacer que sean más rápidas (no voy a entrar en que significa rápido, por si acaso). En otras ocasiones, tenemos desarrolladores que quieren que su código se ejecute más rápido, no se a que tanta prisa la verdad 🙂
Y también de vez en cuando tenemos que crear índices para que eso suceda, pero ¿ahí se acaba la cosa? ¿Estás seguro de que tener el índice es suficiente? ¿Va a servir de algo? Vamos a ver, aquí está tu índice, ¿ahora qué?
Antecedentes
Los beneficios de tener un índice son bien conocidos, podemos obtener los mismos resultados leyendo una cantidad menor de datos, por lo que la mejora en el rendimiento puede ser de varios minutos a segundos o incluso menos.
Eso suena increíble y ciertamente lo es, hay personas que viven de ello, así que obviamente es bastante importante.
Pero no siempre es así, y las cosas pueden salir mal fácilmente y convertir a todos estos índices en una carga inútiles.
Dejadme que os muestre algunos ejemplos, donde podemos ver nuestros índices en uso, pero también cómo el procesador de consultas puede ignorarlos y volverse totalmente inútiles. Voy a utilizar la base de datos de ejemplo de Microsoft [WideWorldImporters] para que podaís seguir conmigo si queréis.
Comportamiento deseado
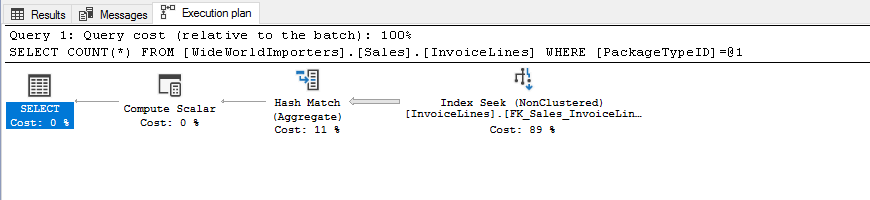
Si comprobamos la tabla [Sales].[InvoiceLines], podemos observar que hay un índice no agrupado en [PackageTypeID], por lo que esperamos que las consultas que utilicen esta columna para filtrar los resultados se pueden beneficiar de él. Exáctamente como esta
USE [WideWorldImporters] SELECT COUNT(*) FROM [Sales].[InvoiceLines] WHERE [PackageTypeID] = 9
Y aquí tenemos otro ejemplo.
USE [WideWorldImporters] SELECT * FROM [Sales].[InvoiceLines] WHERE [PackageTypeID] = 1
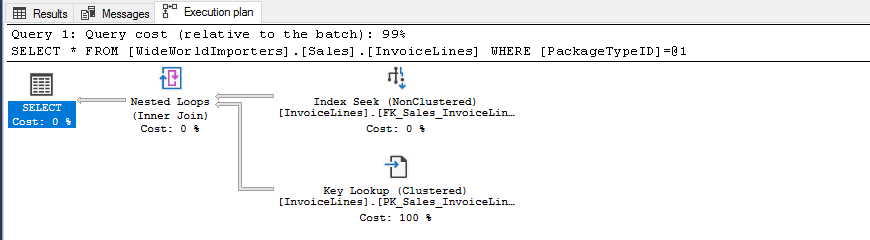
Este segundo ejemplo no es tan bueno como el primero, ya que también debemos realizar búsquedas en la tabla para satisfacer la consulta porque estamos solicitando más columnas que las que existen en el índice.
Inhibidores de búsqueda de índices
Pero no todo es arco iris y unicornios, hay días en que los índices son inútiles, no es su culpa, generalmente la nuestra, pero al final no importa, nuestros índices son inútiles.
Estadísticas
Hemos visto que la primera consulta es el ejemplo perfecto de lo que estamos buscando, leyendo sólo de nuestro índice y sólo las filas que nos interesan.
El segundo ejemplo ya se empieza a salir del buen camino y tiene que añadir otra operación para obtener el resto de las columnas que no están incluidas en nuestro índice no agrupado.
Siguiendo este segundo ejemplo, podemos encontrar nuestro primer inhibidor, que incluyo en este post aunque se puede decir que es «benigno».
El procesador de consultas usa las estadísticas para determinar el mejor plan de consulta para cada consulta y, a veces, es más eficiente leer la table entera que buscar en un índice no agrupado más búsquedas para obtener el resto de columnas.
USE [WideWorldImporters] SELECT * FROM [Sales].[InvoiceLines] WHERE [PackageTypeID] = 9
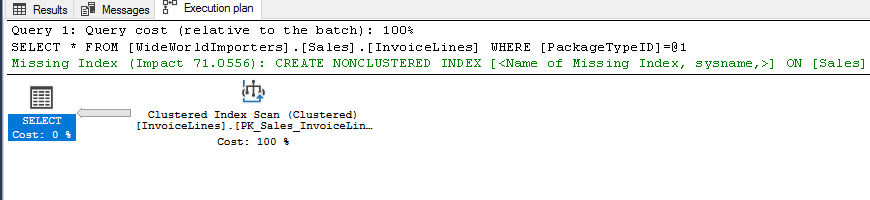
¿He dicho estadísticas?, vamos a echar un vistazo
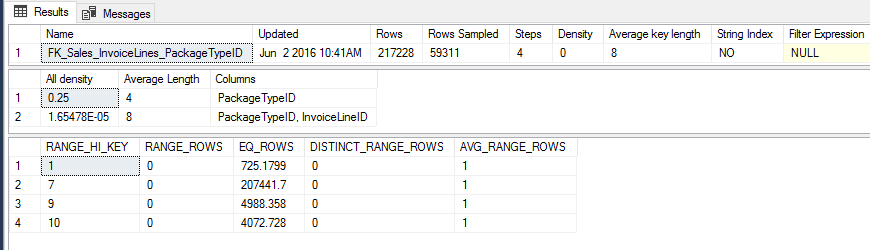
Observad cómo cuando usamos el valor 1, el optimizador cree que Seek + Lookup es el más eficiente considerando que solo hay ~ 725 filas, pero para el valor 9 hay ~ 4988 filas, demasiadas búsquedas, por lo tanto, el plan es simplemente escanear toda la tabla y elige aquellas filas que coinciden con el filtro.
En algún lugar entre el número de filas para el valor 1 y 9 hay un punto llamado «punto de inflexión» una fila por encima de ese umbral y el optimizador cambiará el plan de buscar a escanear. Esto no es necesariamente algo malo. El optimizador suele saber mejor que nosotros cuál es el mejor plan la mayoría de las veces.
Variables
Otro problema que podemos tener cuando el optimizador mira las estadísticas del índice es si no estamos proporcionando un valor sino una variable. Ahora el optimizador tiene que adivinar cuántas filas se devolverán para este valor desconocido antes de ejecutar la consulta.
Veamos nuestro valor 1 cuando está en una variable.
USE [WideWorldImporters] DECLARE @PackageTypeID INT = 1 SELECT * FROM [Sales].[InvoiceLines] WHERE [PackageTypeID] = @PackageTypeID -- Estimated rows = 57066 -- Query plan Clustered Index Scan GO
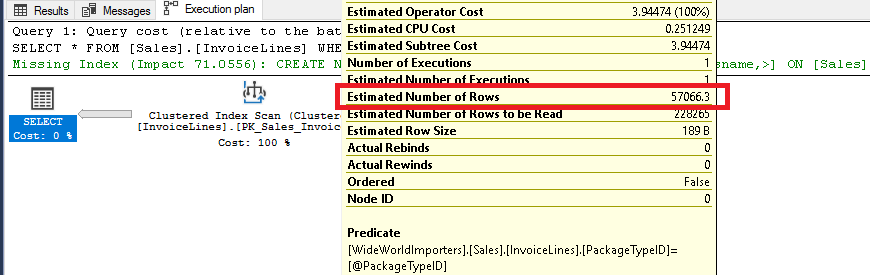
El optimizador calcula cuántas filas por valor en promedio, para adivinar cuántas filas se devolverán y si este número supera el punto de inflexión, el plan es escanear la tabla entera.
Teniendo en cuenta la cardinalidad de esta columna (índice) donde el número de filas para la mayoría de los valores y el promedio supera el punto de inflexión, sería más sensato si siempre realizamos un escaneo de tabla.
Todo esto hace que nuestro índice sea totalmente inútil en la mayoría de los casos …
Más problemas relacionados con estadísticas, detección de parámetros
Ejecutar las consultas de arriba tal y como están, probablemente no sea lo que hacemos normalmente. Por lo general, escribimos procedimientos almacenados por aquello de reutilizar el código y eso.
El problema es que si la primera vez que ejecutamos el procedimiento proporcionamos el valor 1, el plan sería «Seek + Lookup» y será así independientemente del valor en las ejecuciones posteriores, mientras el plan esté en memoria.
Si el primer valor es 9, entonces leer la table entera sería la elección.
No voy a profundizar en esto ya que el tema es lo suficientemente amplio como para tener una publicación o sesión completa, simplemente haced una busqueda en Bing/Google y veréis posibles soluciones para este problema.
Mal T-SQL
Porque seamos honestos, a veces escribimos código que apesta.
Imaginemos que tenemos otro índice que en ambos casos, para valores específicos o para variables, siempre devuelve index seek + key lookup y que también es la forma más eficiente … ¿Cómo suena eso? bien, ¿no?
Y ahora imaginaos que escribimos nuestro código y lo fastidiamoes 🙁
DBCC SHOW_STATISTICS ('[Sales].[InvoiceLines]', [FK_Sales_InvoiceLines_StockItemID])
/*
Avg -> Rows * All density = 951
RANGE_HI_KEY EQ_ROWS
1 1097.179
2 991.8209
3 999.087
4 1060.849
... ...
*/
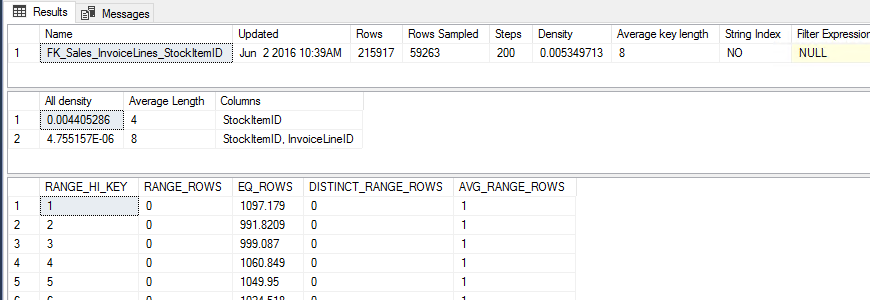
Los valores están distribuidos uniformemente, de modo que tanto cada valor como el promedio (utilizando una variable) produce el mismo plan de consulta, seek + lookup.
USE [WideWorldImporters] SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = 1 -- Estimated rows = 1159 -- Query plan Index Seek + Key Lookup GO DECLARE @StockItemID INT = 1 SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = @StockItemID -- Estimated rows = 1005 -- Query plan Index Seek + Key Lookup GO
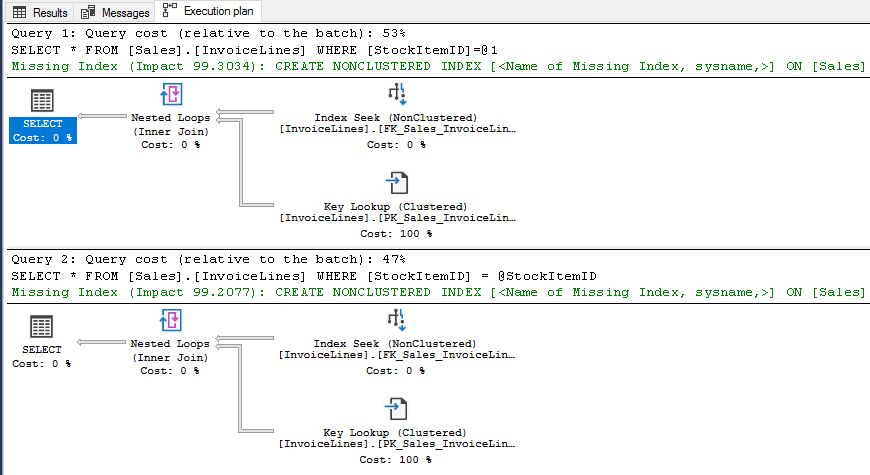
Este ejemplo es perfecto, entonces, ¿qué puede salir mal?, fácil, ¿cuántas veces tenemos que escribir código como este?
USE [WideWorldImporters] DECLARE @StockItemID INT = 1 SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = @StockItemID OR @StockItemID IS NULL
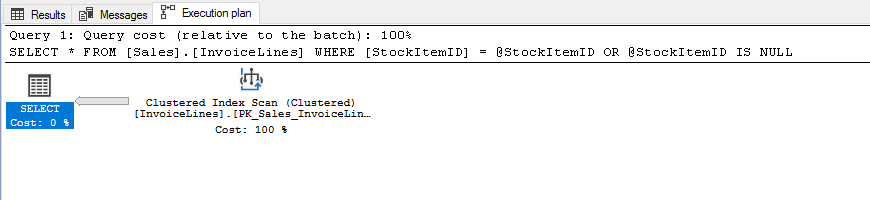
BOOOM!!! ahí lo tienes, aquí esta tu índice que no vale para nada.
¿Y que hacemos ahora?
Pues mala solución tiene el asunto, y como suele decirse, «depende».
Obviamente habría que tener en cuenta muchos factores, porque es raro que tengamos un proceso tán simple como una consulta. La complejidad del mismo así como la frecuencia con la que llamamos a este proceso pueden ser determinantes.
Una de las posibles soluciones sería usar dos consultas en vez de una y ejecutar una u otra en función del valor del parámetro.
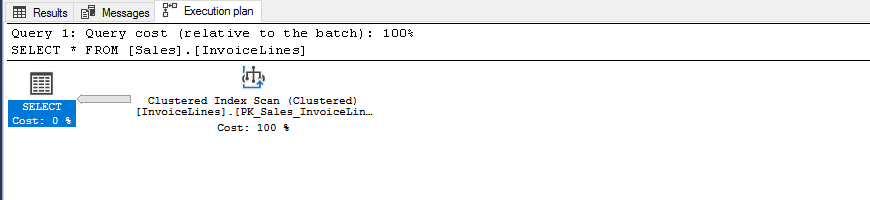
DECLARE @StockItemID INT = 1 IF @StockItemID IS NULL BEGIN SELECT * FROM [Sales].[InvoiceLines] END ELSE BEGIN SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = @StockItemID END
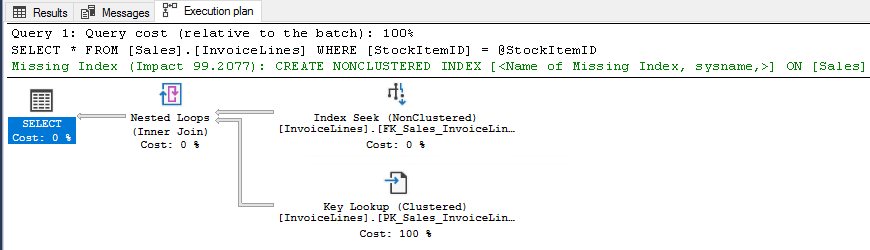
Y si pasamos NULL, entoces tenemos
La otra opción sería usar OPTION(RECOMPILE), pero hay que tener cuidado con esta solución por el posible impacto en el rendimiento general del servidor ya que recompilar tiene un coste de CPU que hay que tener en cuenta.
Quedaría algo así como
USE [WideWorldImporters] DECLARE @StockItemID INT = 1 SELECT * FROM [Sales].[InvoiceLines] WHERE [StockItemID] = @StockItemID OR @StockItemID IS NULL OPTION(RECOMPILE)
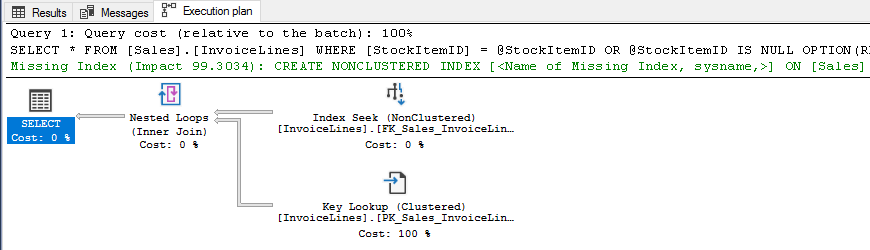
Conclusión
Habéis visto lo fácil que las cosas pueden torcerse y hacer que nuestro nuevo y brillante índice sea absolutamente inútil. Este ha sido solo un ejemplo, pero espero que sea suficiente como para haceros reflexionar acerca de lo difícil que es optimizar consultas para mejorar el rendimiento.
Gracias por leer y por favor dejadme en los comentarios lo que pensais sobre este u otros casos que os hayan pasado.