Los planes de ejecución son muy útiles a las hora de mejorar la eficacia de nuestras consultas, pero muchas veces tratamos de evitar algunos operadores o culparlos de los problemas de rendimiento cuando no siempre son los autenticos culpables, dejadme enseñaros uno de esos casos en que la teoría no se ajusta a la realidad Entiendo que si quieres mantenerte al día con la tecnología (o al menos intentarlo), debes pasar gran parte de tu tiempo leyendo sobre ella, sin importar si usas libros en línea, compras libros de la tienda o lo que más disfruto, leer publicaciones de blogs y artículos técnicos.
Así que estoy leyendo un artículo de Klaus Aschenbrenner (b|t) llamado The Performance Penalty of Bookmark Lookups in SQL Server que explica la degradación del rendimiento que puede sufrir debido al operador bookmark (or Key) lookups.
Todo bien, es un reputado experto y sabe de lo que está hablando y no pretendo decir que está equivocado, porque no lo está, pero déjadme mostraros el 0,000001% que hace que SQL Server sea un sistema tan fascinante.
Antecedentes
No voy a entrar en muchos detalles sobre los Key Lookups ya que puedes leer el artículo de Klaus, que obviamente recomiendo, pero como siempre hay un ‘depende’. Y voy a mostrarte algo que encontré la semana pasada y mantuve los planes de ejecución para explicar.
Como dije, 99.999999% (suposición es educada) de los tiempos, el optimizador de consultas elegirá un índice de cobertura, ya que solo tiene que leer de un sitio para finalizar la consulta, evitando costosos operadores de bucle anidados y las búsquedas temibles. A mi me parece bastante razonable.
Pero en algunas condiciones y donde hay otro índice que se pueda usar, el optimizador puede elegir (sabiamente) utilizar ese índice y luego realizar las búsquedas. Déjame mostrarte las consultas y sus planes de ejecución.
SELECT DISTINCT
Object1.Column1 ,
Object1.Column2 ,
Object1.Column3 AS Column4 ,
Object1.Column5 AS Column6 ,
Object1.Column7 AS Column8
FROM Schema1.Object2 AS Object1
INNER JOIN Schema1.Object3 AS Object3
ON Object1.Column1 = Object3.Column1
INNER JOIN Schema1.Object4 AS Object5
ON Object3.Column10 = Object5.Column11
WHERE Object1.Column12 = 'Value'
AND Object1.Column3 BETWEEN 'Date' AND 'Date'
AND ( Object5.Column13 LIKE '%String%' );
SELECT DISTINCT
Object1.Column1 ,
Object1.Column2 ,
Object1.Column3 AS Column4 ,
Object1.Column5 AS Column6 ,
Object1.Column7 AS Column8
FROM Schema1.Object2 AS Object1 WITH ( INDEX = Index5 )
INNER JOIN Schema1.Object3 AS Object3
ON Object1.Column1 = Object3.Column1
INNER JOIN Schema1.Object4 AS Object5
ON Object3.Column10 = Object5.Column11
WHERE Object1.Column12 = 'Value'
AND Object1.Column3 BETWEEN 'Date' AND 'Date'
AND ( Object5.Column13 LIKE '%String%' );
La primera consulta no utilizaba el índice de cobertura que había creado, así que decidí forzarlo en la segunda consulta, los planes de ejecución son los siguientes
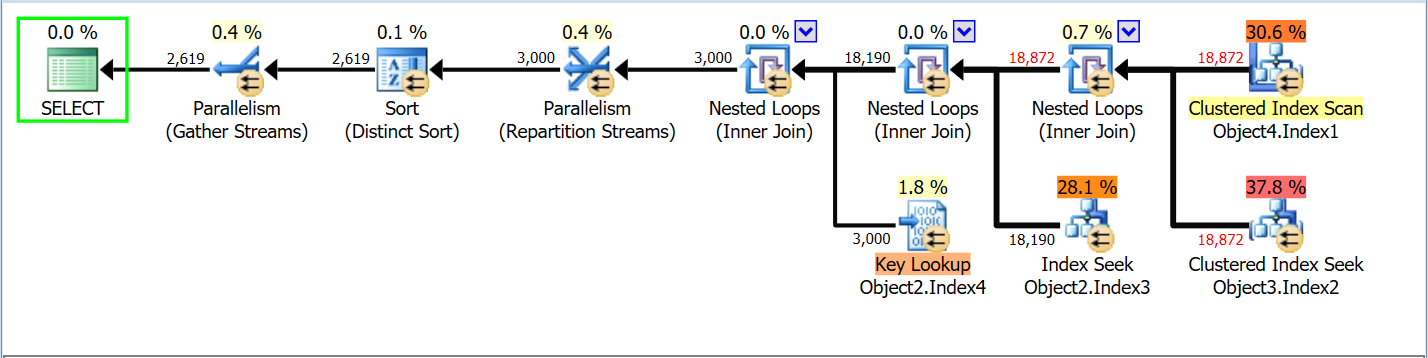
Puedes ver que hay Key Lookups, y realmente me intrigó esto, ¿se me ha pasado añadir una columna para cubrir la consulta? Así que decidí usar una sugerencia de consulta para forzar el índice de cobertura. Y este fué el plan de ejecución
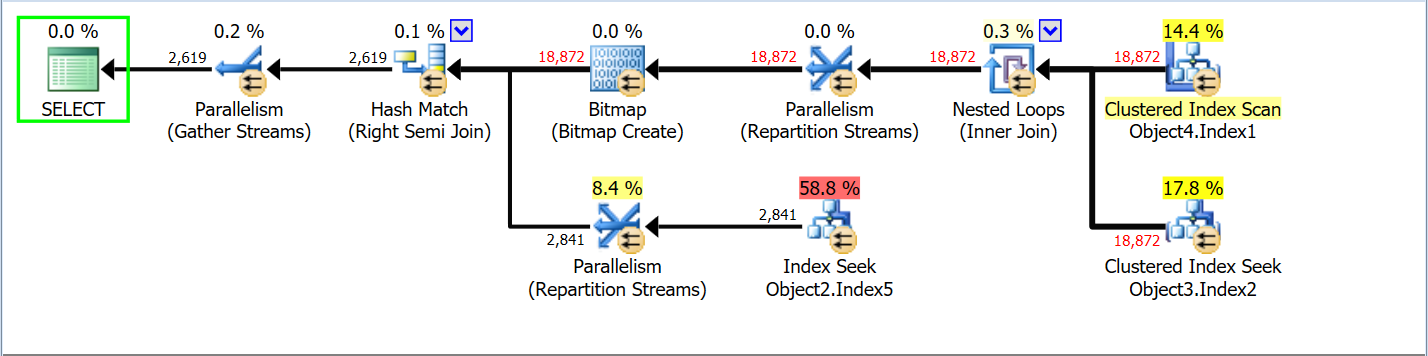
Se puede observar cómo Object2.Index3 Seek + Object2.Index4 Lookup se ha convertido en Object2.Index5 Seek. Y en teoría, eso debería ser más barato para SQL Server, entonces ¿en qué está pensando? ¿Se ha vuelto loco o algo así?
Realmente no.
Sigamos investigando
Los planes de ejecución son buenos para el ajuste del rendimiento, pero estas no son las únicas herramientas que debemos analizar. Otra gran herramienta es STATISTICS IO y STATISTICS TIME, siendo esta última un poco más ~ish en algunos aspectos, pero en general ambos son los que uso todo el rato para optimizar el SQL.
El resultado para estas dos consultas es
/* (2619 row(s) affected) Table 'Object2'. Scan count 0, logical reads 150702, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Object3'. Scan count 0, logical reads 76737, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Object4'. Scan count 9, logical reads 64938, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) SQL Server Execution Times: CPU time = 19716 ms, elapsed time = 2632 ms. (2619 row(s) affected) Table 'Object3'. Scan count 0, logical reads 76735, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Object4'. Scan count 9, logical reads 64938, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Object2'. Scan count 9, logical reads 293220, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) SQL Server Execution Times: CPU time = 24297 ms, elapsed time = 3071 ms. */
Si usamos StatisticsParser obtenemos una imagen mucho más bonita
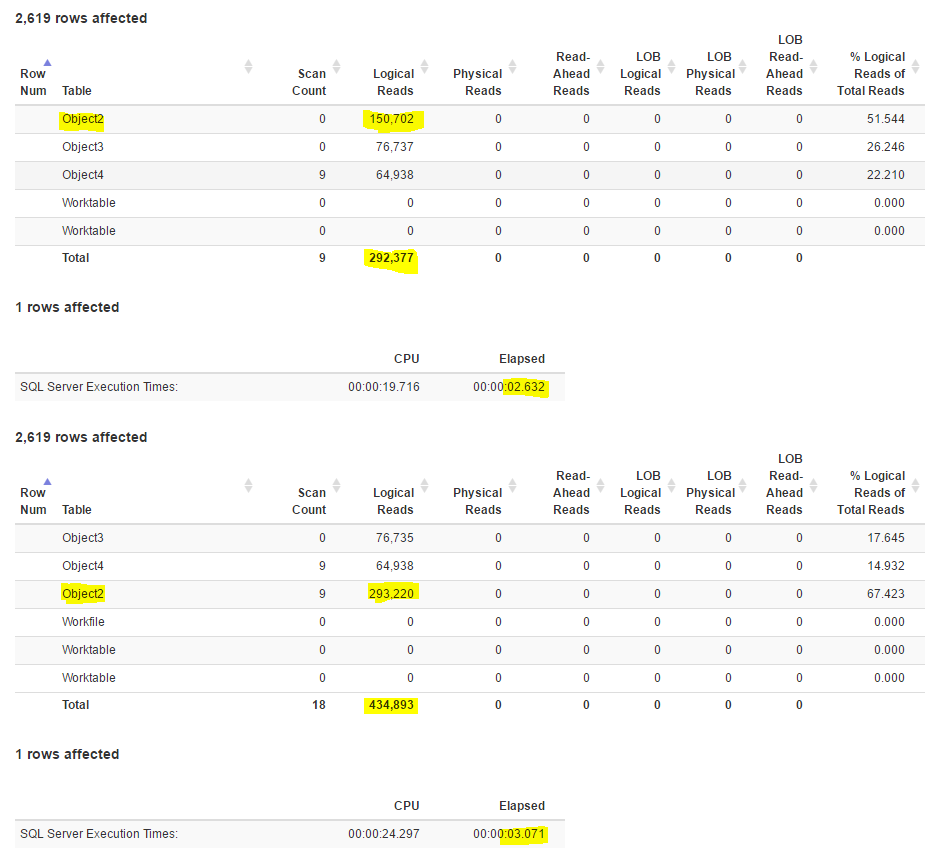
En la primera consulta (la elección del optimizador), la tabla más grande tiene casi la mitad de las lecturas, incluidos los dos índices, en el que buscamos por la clave y el que hacemos el lookup para obtener el resto de columnas.
Obligar a SQL a usar el índice de cobertura en este caso no ayuda, ya que necesita casi el doble de esfuerzo para satisfacer la misma consulta.
La trampa
Este es un caso muy especial donde el índice de cobertura tiene tres claves y luego un par de columnas incluidas, una de las cuales es la columna NVARCHAR (MAX), por lo que el índice de cobertura es bastante grande y solo buscamos en la columna de la izquierda, que también es posible utilizando otro índice mucho más pequeño en esa única columna.
En ambos casos, el operador puede enviar el (los) predicado(s) de la consulta a la búsqueda y, gracias a eso, el número de filas que sale del operador no es tan grande. Pero el número de filas que coinciden con la clave más a la izquierda y, por lo tanto, deben leerse es bastante grande.
Recuerde que aunque vea «Buscar» lo que es en realidad un escaneo parcial y dependiendo de qué tan grande es la porción para escanear y el número de filas que caben en una página, el optimizador usaría el índice más estrecho, ya que podría contrarrestar la penalización de tener que hacer Lookups para las filas retornadas.
Así que tomé la consulta y la dividí de forma que coincida con el operador lógico, teniendo una consulta común a los dos planes de ejecución diferentes y luego dos variaciones, con una única búsqueda para el índice de cobertura y otra con dos la búsqueda más la búsqueda.
Y mirar el resultado de STATISTICS IO es bastante revelador:
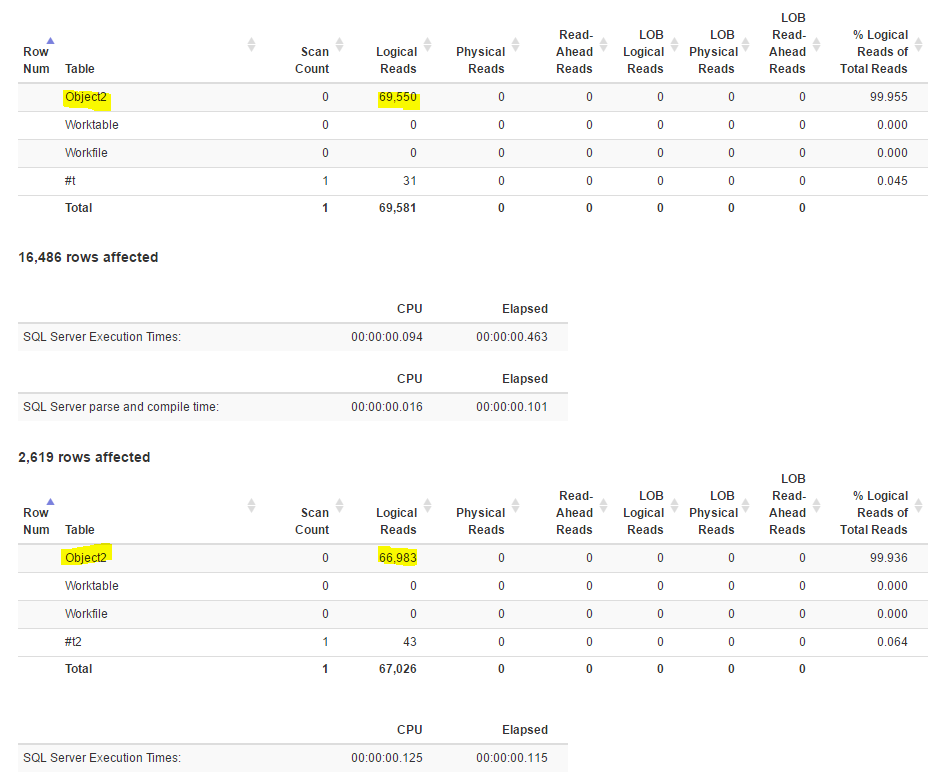
Ambas consultas causan menos lecturas en total, lo que significa que los dos operadores (búsqueda + lookup) son, en este caso, menos costosos en IO que una búsqueda (escaneo parcial) en el índice de cobertura más amplio.
Podemos ver ambos para comparar uno al lado del otro.
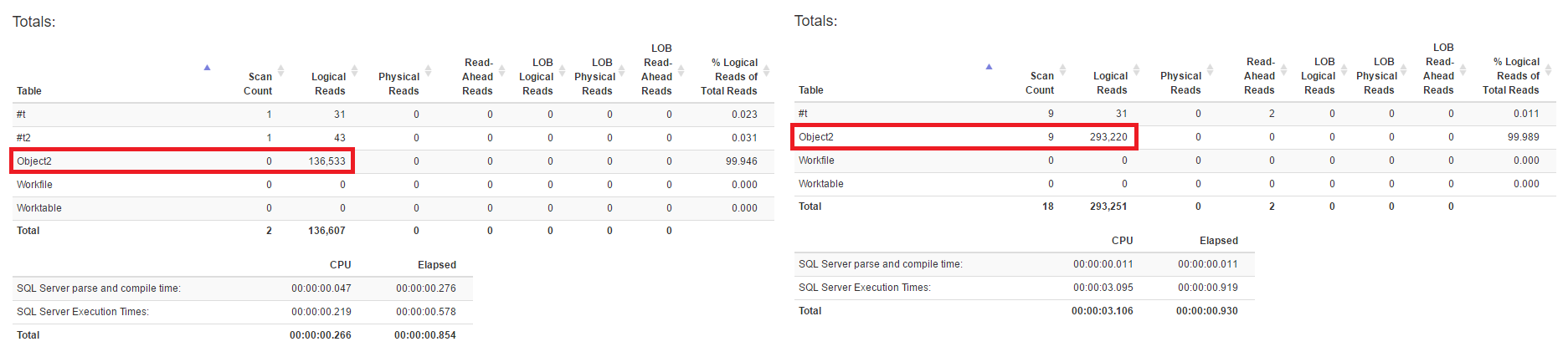
El lado izquierdo intenta replicar las dos búsquedas mediante el uso de dos tablas temporales de etapas y el de la derecha usará el índice de cobertura.
Entonces, debido al tamaño del índice de cobertura y la cardinalidad de la columna de la izquierda, el optimizador cree que usar el índice más estrecho y luego buscar las columnas restantes para las filas sería más barato que mirar el índice de cobertura, que resulta en más IO’s, cerca del doble de lecturas.
Conclusión
Esta es una demostración de lo difícil que puede ser ajustar y optimizar las consultas para el rendimiento y los muchos factores que pueden estar involucrados.
Los hechos explicados no contradicen la regla general, pero si hay más factores involucrados, esta puede ser ignorada. También viene de nuevo para demostrar que casi nunca una solución funciona en absolutamente todos los casos cuando se habla de SQL Server, aunque se trata de una caso bastante extraño.
Obviamente, debemos seguir las guías de buenas prácticas porque cubrirán la gran mayoría de los casos, pero aunque las sigamos, aún podemos encontrar cosas que nos sorprendan.
He tratado de replicar con diferentes conjuntos de valores y el índice de cobertura fue la opción preferida más común, lo que hace que valga la pena incluso si hay algunas excepciones.
Gracias por leer y cualquier pregunta, usad los comentarios!